
流行病学重点
5页
1、1、 流行病学研究内容的三个层次:疾病、伤害和健康;流行病学任务的三个阶段:第一阶段是“揭示现象” 第二阶段是“找出现象” 第三阶段是“提供措施”2、 流行病学的特征(观点):群体的特征、对比的特征、概率论和数理统计学的特征、社会心理的特征、预防为主的特征、发展的特征(填空题)3、 发病率表示在一定时期内,一定人群中某病新发生的病例出现的频率。患病率是某特定时间内一定人群中某病新旧病例所占比例。4、 患病率和发病率是区别:患病率取决于两个因素,即发病率和病程,因此患病率的变化可反映出发病率的变化或疾病结果的变化或两者兼有。患病率下降既可由于发病率下降,也可由于病人恢复快或死亡快,病程缩短所致。当某地某病的发病率和该病的病程在相当长时间内保持稳定时,患病率、发病率和病程三者的关系是:患病率=发病率*病程。5、 疾病流行的强度:散发是指发病率呈历年的一般水平,各病例间在发病时间和地点方面无明显联系,散在发生。暴发是指在一个局部地区或集体单位中,短时间内突然有很多相同的病人出现。流行是指某病在某地区显著超过该病历年发病率水平。大流行是指某病有时迅速蔓延可跨越一省、一国或一州,其发病率水平超过
2、该地一定历史条件下的流行水平。6、 疾病年龄分布的分析方法:a、横断面分析的优缺点:多用于发病率、死亡率等没有明显长期变动趋势的疾病的分析,但不能正确显示致病因子与年龄的关系。b、年龄期间队列分析,是利用出生队列资料将疾病年龄分布和时间分布结合起来描述的一种方法,它在评价疾病的年龄分布长期变化趋势及提供病因线索等方面具有重要意义。7、 时间分布的类型:短期波动、季节性、周期性、长期趋势(选择题)8、 地方性疾病是指局限于某些特定地区内相对稳定并经常发生的疾病。判断一种疾病是否属于地方性疾病的依据是:a、该地区的各类居民、任何民族的发病率均高。b、在其他地区居住的相似的人群中该病的发病频率均低,甚至不发病。c、迁入该地区的人经一段时间后,其发病率和当地居民一致。D、人群迁出该地区后,发病率下降或患病症状减轻或自愈。E、除人之外,当地的易感动物也可发生同样的疾病9、 移民流行病学是对移民人群的疾病分布进行研究,以探讨病因。他是通过观察疾病在移民、移民移入国当地居民及原居地人群间的发病率、死亡率的差异,从其差异中探讨病因线索,区分遗传因素或环境因素作用的大小。10、 描述性研究又称描述流行病
3、学,是指利用常规监测记录或通过专门调查获得的数据资料包括实验室检查结果,按照不同地区、不同时间及不同人群特征分组,描述人群中疾病或健康状态或暴露因素的分布情况,在此基础上进行比较分析,获得疾病三间分布的特征,进而提出病因假设和线索。11、 现况研究是通过对特定时点(或期间)和特定范围内人群中的有关变量(因素)与疾病或健康状况关系的描述,为研究的纵向深入提供线索和病因学假设。12、 抽样的方法:单纯随机抽样、系统抽样、分层抽样、整群抽样、多阶段抽样。13、 队列研究是将人群按是否暴露于某可疑因素及暴露程度分为不同的亚组,追踪其各自的结局,比较不同亚组之间结局频率的差异,从而判定暴露因子与结局之间有无因果关联及关联大小的一种观察性研究方法。14、 队列研究的特点:属于观察法、须设立对照组、由因及果的研究、能确证暴露与结局的因果联系。15、 队列研究的类型:前瞻性队列研究、历史性队列研究、双向性队列研究16、 怎样选择队列研究的研究人群(论述题):暴露人群的选择有职业人群、特殊暴露人群、一般人群、有组织的人群团体。对照人群的选择由内对照、外对照、总人口对照和多重对照。(要详细点)17、 率的
4、计算,常用指标由累计发病率和发病密度及标化比,其中发病密度需以观察人时为分母计算发病率。18、 效应的估计:相对危险度(RR)是暴露组的危险度(测量指标是累计发病率)与对照组的危险度之比。它是反映暴露与发病(死亡)关联强度的最有用的指标。归因危险度又叫特意危险度(AR)是暴露组发病率与对照组发病率相差的绝对值。它表示危险特异地归因于暴露因素的程度。RR和AR都是表示关联强度的重要指标,彼此密切相关,但其流行病学意义却不同。RR说明暴露者与非暴露者比较相应疾病危险增加的倍数;AR则是指暴露人群与非暴露人群比较,所增加的疾病发生数量。如果暴露因素消除,就可减少这个数量的疾病发生。前者具有病因学的意义,后者更具有疾病预防和公共卫生学上的意义。19、 匹配或称配比,即要求对照在某些因素或特征上与比例保持一致,目的是对两组进行比较时排除匹配因素的干扰,从而更正确地说明所研究因素与疾病的关系。匹配分为频数匹配和个体匹配。20、 病例与对照的基本来源有2个:一个来源是医院的现患病人或医院和门诊的病案及出院记录记载的既往病人,称以医院为基础的。另一个来源是社区、社区的监测资料或普查、抽查的人群资料,称
《流行病学重点》由会员新**分享,可在线阅读,更多相关《流行病学重点》请在金锄头文库上搜索。

unit2全单元教案

快乐的一周周记(精选23篇).doc

学校消防安全管理责任人任命书及职责.doc
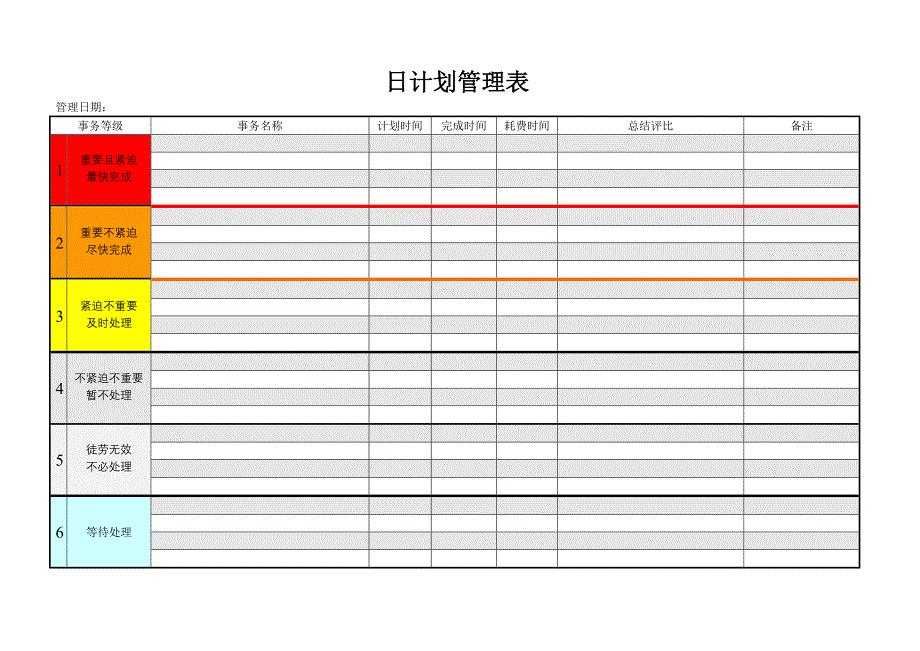
2021-2022年日、周、月、年计划管理套表

FLL课题研究要求

混凝土工程承包合同书

国庆节慰问信四篇

政排水管道工程项目施工质量通病分析及预防措施

南开大学21春《金融工程学》在线作业三满分答案69

英语演讲稿MakeEveryMomentCount

审计需整改情况说明

2023年最新酒店财务工作计划范文(四篇).doc

2022年考博英语-外交学院考试题库(难点、易错点剖析)附答案有详解7

加工合同格式

锚索检测方案

高三2023年班主任工作总结(3篇).doc

管理员个人工作总结范本(3篇).doc

2022银行存款营销工作计划

两款威力最大的电棍

2023年上半年北京房地产估价师制度与政策房地产中介服务行业自律考试试题
 恒压供水毕业设计.doc
恒压供水毕业设计.doc
2023-12-09 37页
互联网自助洗车机项目商业计划书.doc
2023-03-22 8页
市场监管系统抗击新冠肺炎先进典型事迹
2022-12-19 3页
医学复习资料:急诊医学知识题库选择题部分(附答案)
2022-10-11 16页
劳动合同(广州市标准版)
2022-12-25 10页
物业经理工作职责具体内容
2022-08-03 7页
教师暑期政治学习心得体会范文
2023-09-22 3页
市财政局教科文科工作计划(精简版)
2023-06-29 5页
2019年电信支局长述职报告.doc
2023-12-17 8页
( )区、县级疫情防控工作总结汇报----以我们“辛苦指数”换来你们“平安指数”和“幸福指数”值!.docx
2022-11-14 5页