
深度学习在金融领域的应用
48页
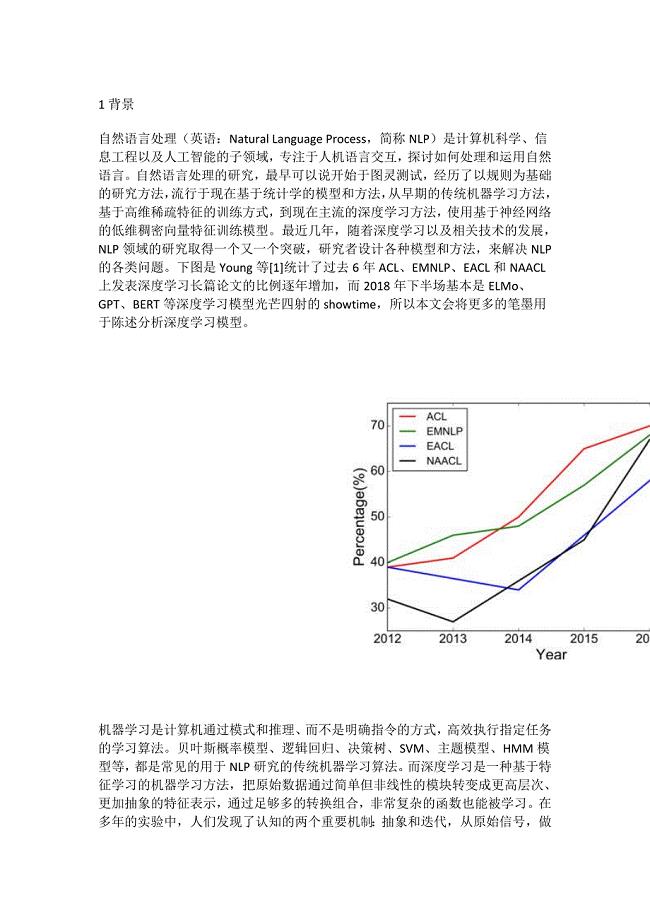
1、深度学习在金融领域的应用现在我们正处在一个深度学习时代,CV领域基本上已经被NN所统治,NLP、推荐也有不同程度的大规模应用。似乎很多从业者对风控领域的认知是我们一定不会使用深度学习方法,归根结底是因为它本身是一个黑箱模型,解释性较差。但是个人理解当我们从LR转向XGBoost的时候,解释性其实就已经不复存在了。纵观整个机器学习界,无外乎都是从传统机器学习逐渐过渡到NN的一个过程,个人觉得深度学习在各个领域的普及是迟早的事情。那么当前深度学习在风控场景都有哪些应用呢?我觉得基本可以总结为以下这三个子场景:1)序列数据建模:代表算法 LSTM2)图谱建模:代表算法 GCN3)传统特征衍生:代表算法 CNN、XDeepFM循环神经网络目前就使用场景来看,与传统风控建模手段区别最大的,莫过于基于RNN的一系列序列模型,不在使用onehot编码或者时间窗口的描述统计特征进行建模,而是使用循环神经网络对时间序列进行拟合,从而学习到一个用户的发展变化。代表场景主要是拥有时间顺序的序列数据: B卡 盗号检测 失联模型 文本分类理论上来说用户在app上的点击数据都可以拿来使用。卷积神经网络CNN中的卷
2、积本质上就是利用一个共享参数的过滤器(kernel),通过计算中心像素点以及相邻像素点的加权和来构成feature map实现空间特征的提取,加权系数就是卷积核的权重系数。代表场景主要是用于拥有拓扑关系的数据上 将可以求和的数据展开成feature-map的样子即可做卷积,从而实现特征交叉,挖掘更深层次的特征深度学习的另一个非常重要的领域就是在我们的知识图谱中。图卷积神经网络的前奏-Node2Vec说GCN之前首先要先知道一个概念叫做Node2Vec,讲Node2Vec之前可能需要先引入一个概念叫做Word2VecWord2Vec的基本流程如下那我们怎么在图中找到“临近”的节点?如何生成节点序列?1)广度优先遍历(BFS)从根节点出发,即下图中的0节点出发首先访问它的子节点1,之后再访问它的子节点2。当根节点0的所有子节点访问完了,再访问节点1的子节点,即节点3和节点4当节点1的所有子节点访问完了,再访问节点2的所有子节点,即节点5和节点6访问顺序为0-1-2-3-4-5-6广度优先遍历得到的是结构相似性 (structural equivalence):结构相似性是衡量两个节点在网络
3、中所在的位置和结构的相似性。2)深度优先遍历(DFS)从根节点0出发首先访问它的子节点1, 然后再访问节点1的子节点,节点3和节点4再返回访问子节点2,然后再访问节点2的子节点,节点5和节点6访问顺序为 0-1-3-4-2-5-6深度优先遍历得到的是同质性(homophily):通过两个节点的距离来衡量它们之间的相似性。如果两个节点的距离越近,则它们的同质性越高,也就是相似度越大。那么,有没有可能在某种生成节点序列的过程中同时考虑到homophily和structural equivalence?Random Walk 随机游走随机漫步(Random Walk)思想最早由Karl Pearson在1905年提出,它是一种不规则的变动形式,在变动过程当中的每一步都是随机的。假如我们有下面这样一个小的关系网络。在加权网络结构图,我们还可以根据权重来设置某节点游走到另外一个节点的概率。随机游走在生成节点序列中,在一定程度上既可以照顾到homophily,又可以照顾到structural equivalence。但是很难控制两种相似性所占的比重。node2vecnode2vec 可以改善ran
4、dom walk,更好地反映同质性与结构相似性以下图为例,选择 t 为初始节点,并引入两个参数 p和q返回概率参数(Return parameter)p,对应BFS,p控制回到原来节点的概率,如图中从t跳到v以后,有1/p的概率在节点v处再跳回到t离开概率参数(In outparameter)q,对应DFS,q控制跳到其他节点的概率假设现在已经从节点 t 走到节点 v,那么边的权重如所示:其中dtx表示节点t到节点x之间的最短路径通过上面我们可以发现: q 越大,p越小,结构相似性所占比重越高 p 越大,q越小,同质性所占比重越高图卷积神经网络(Graphs Convolutional Neural Networks )CNN处理的图像或者视频数据中像素点(pixel)是排列成成很整齐的矩阵。与之相对应,科学研究中还有很多Non Euclidean Structure的数据,社交网络、信息网络中有很多类似的结构。实际上,这样的网络结构(Non Euclidean Structure)就是图论中抽象意义上的拓扑图。因此我们提出GCN.为什么要研究GCN? CNN无法处理Non Eucli
《深度学习在金融领域的应用》由会员一***分享,可在线阅读,更多相关《深度学习在金融领域的应用》请在金锄头文库上搜索。
















 2023 年最常见的人工智能面试问题(精选)
2023 年最常见的人工智能面试问题(精选)
2023-08-27 48页
如何在人工智能机器学习中实现分类?
2023-08-23 18页
智慧病房解决方案
2022-03-22 4页
021801物联网技术解析
2022-02-19 14页
021802人工智能的发展与研究
2022-02-19 28页
游戏人工智能的发展与展望(经典实用)
2021-09-20 18页
网点智能化转型模式(经典实用)
2021-09-20 14页
青海海东科技园概念性规划说明(经典实用)
2021-09-20 11页
论青海花儿的创新与发展(经典实用)
2021-09-20 26页
试用期个人工作总结10篇(经典实用)
2021-09-20 27页