
解读NLP深度学习的各类模型
45页
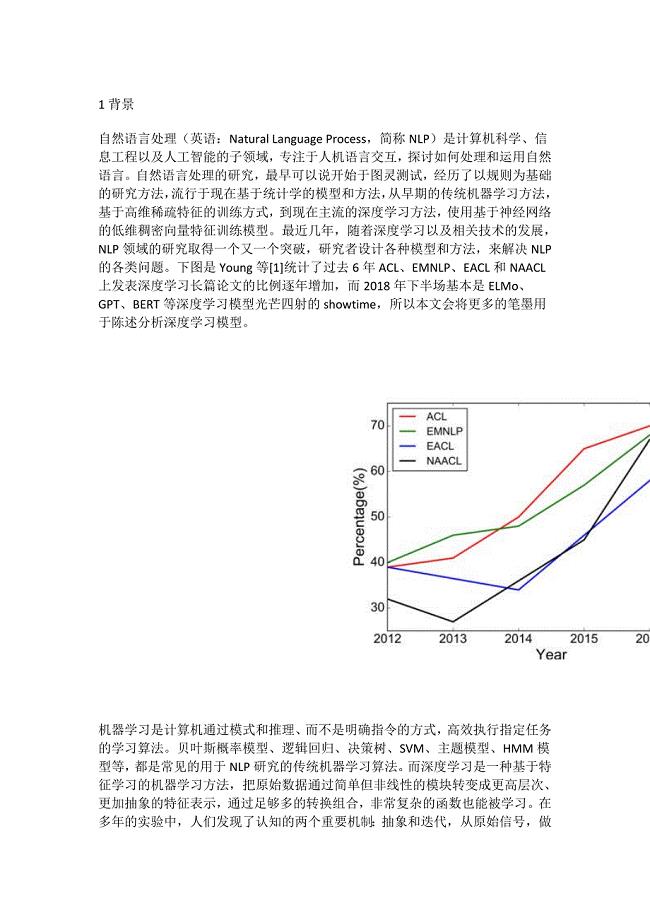
1、1背景自然语言处理(英语:Natural Language Process,简称NLP)是计算机科学、信息工程以及人工智能的子领域,专注于人机语言交互,探讨如何处理和运用自然语言。自然语言处理的研究,最早可以说开始于图灵测试,经历了以规则为基础的研究方法,流行于现在基于统计学的模型和方法,从早期的传统机器学习方法,基于高维稀疏特征的训练方式,到现在主流的深度学习方法,使用基于神经网络的低维稠密向量特征训练模型。最近几年,随着深度学习以及相关技术的发展,NLP领域的研究取得一个又一个突破,研究者设计各种模型和方法,来解决NLP的各类问题。下图是Young等1统计了过去6年ACL、EMNLP、EACL和NAACL上发表深度学习长篇论文的比例逐年增加,而2018年下半场基本是ELMo、GPT、BERT等深度学习模型光芒四射的showtime,所以本文会将更多的笔墨用于陈述分析深度学习模型。机器学习是计算机通过模式和推理、而不是明确指令的方式,高效执行指定任务的学习算法。贝叶斯概率模型、逻辑回归、决策树、SVM、主题模型、HMM模型等,都是常见的用于NLP研究的传统机器学习算法。而深度学习是一
2、种基于特征学习的机器学习方法,把原始数据通过简单但非线性的模块转变成更高层次、更加抽象的特征表示,通过足够多的转换组合,非常复杂的函数也能被学习。在多年的实验中,人们发现了认知的两个重要机制:抽象和迭代,从原始信号,做底层抽象,逐渐向高层抽象迭代,在迭代中抽象出更高层的模式。如何形象地理解?在机器视觉领域会比较容易理解,深度学习通过多层神经网络依次提取出图像信息的边缘特征、简单形状特征譬如嘴巴的轮廓、更高层的形状特征譬如脸型;而在自然语言处理领域则没有那么直观的理解,我们可以通过深度学习模型学习到文本信息的语法特征和语义特征。可以说,深度学习,代表自然语言处理研究从机器学习到认知计算的进步。要讲深度学习,得从语言模型开始讲起。自然语言处理的基础研究便是人机语言交互,以机器能够理解的算法来反映人类的语言,核心是基于统计学的语言模型。语言模型(英语:Language Model,简称LM),是一串词序列的概率分布。通过语言模型,可以量化地评估一串文字存在的可能性。对于一段长度为n的文本,文本中的每个单词都有通过上文预测该单词的过程,所有单词的概率乘积便可以用来评估文本存在的可能性。在实践中
3、,如果文本很长,P(w_i|context(w_i)的估算会很困难,因此有了简化版:N元模型。在N元模型中,通过对当前词的前N个词进行计算来估算该词的条件概率。对于N元模型。常用的有unigram、bigram和trigram,N越大,越容易出现数据稀疏问题,估算结果越不准。为了解决N元模型估算概率时的数据稀疏问题,研究者尝试用神经网络来研究语言模型。早在2000年,就有研究者提出用神经网络研究语言模型的想法,经典代表有2003年Bengio等2提出的NNLM,但效果并不显著,深度学习用于NLP的研究一直处在探索的阶段。直到2011年,Collobert等3用一个简单的深度学习模型在命名实体识别NER、语义角色标注SRL、词性标注POS-tagging等NLP任务取得SOTA成绩,基于深度学习的研究方法得到越来越多关注。2013年,以Word2vec、Glove为代表的词向量大火,更多的研究从词向量的角度探索如何提高语言模型的能力,研究关注词内语义和上下文语义。此外,基于深度学习的研究经历了CNN、RNN、Transormer等特征提取器,研究者尝试用各种机制优化语言模型的能力,包括预
4、训练结合下游任务微调的方法。最近最吸睛的EMLo、GPT和BERT模型,便是这种预训练方法的优秀代表,频频刷新SOTA。2模型接下来文章会以循序渐进的方式分成五个部分来介绍深度学习模型:第一部分介绍一些基础模型;第二部分介绍基于CNN的模型;第三部分介绍基于RNN的模型;第四部分介绍基于Attention机制的模型;第五部分介绍基于Transformer的模型,讲述一段语言模型升级迭代的故事。NLP有很多模型和方法,不同的任务场景有不同的模型和策略来解决某些问题。笔者认为,理解了这些模型,再去理解别的模型便不是很难的事情,甚至可以自己尝试设计模型来满足具体任务场景的需求。Basic Embedding ModelNNLM是非常经典的神经网络语言模型,虽然相比传统机器学习并没有很显著的成效,但大家说起NLP在深度学习方向的探索,总不忘提及这位元老。分布式表示的概念很早就有研究者提出并应用于深度学习模型,Word2vec使用CBOW和Skip-gram训练模型,意外的语意组合效果才使得词向量广泛普及。FastText在语言模型上没有什么特别的突破,但模型的优化使得深度学习模型在大规模数据的
《解读NLP深度学习的各类模型》由会员一***分享,可在线阅读,更多相关《解读NLP深度学习的各类模型》请在金锄头文库上搜索。
















 2023 年最常见的人工智能面试问题(精选)
2023 年最常见的人工智能面试问题(精选)
2023-08-27 48页
如何在人工智能机器学习中实现分类?
2023-08-23 18页
智慧病房解决方案
2022-03-22 4页
021801物联网技术解析
2022-02-19 14页
021802人工智能的发展与研究
2022-02-19 28页
游戏人工智能的发展与展望(经典实用)
2021-09-20 18页
网点智能化转型模式(经典实用)
2021-09-20 14页
青海海东科技园概念性规划说明(经典实用)
2021-09-20 11页
论青海花儿的创新与发展(经典实用)
2021-09-20 26页
试用期个人工作总结10篇(经典实用)
2021-09-20 27页