
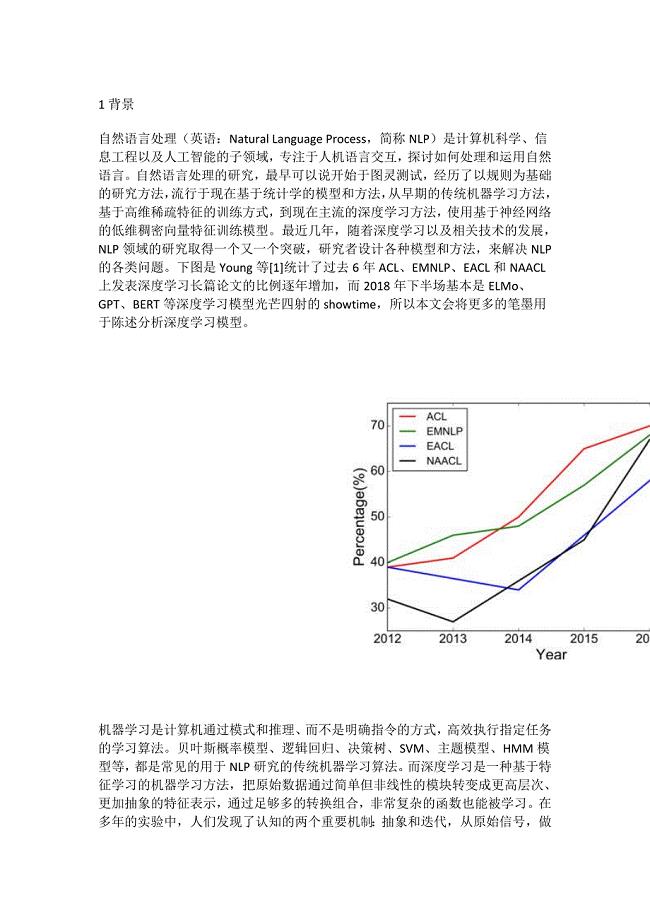
NLP深度学习模型
55页
1、作为数据科学家,你最重要的技能之一应该是为你的问题选择正确的建模技术和算法。几个月前,我试图解决文本分类问题,即分类哪些新闻文章与我的客户相关。我只有几千个标记的例子,所以我开始使用简单的经典机器学习建模方法,如TF-IDF上的Logistic回归,但这个模型通常适用于长文档的文本分类。在发现了我的模型错误之后,我发现仅仅是理解词对于这个任务是不够的,我需要一个模型,它将使用对文档的更深层次的语义理解。深度学习模型在复杂任务上有非常好的表现,这些任务通常需要深入理解翻译、问答、摘要、自然语言推理等文本。所以这似乎是一种很好的方法,但深度学习通常需要数十万甚至数百万的训练标记的数据点,几千的数据量显然是不够的。通常,大数据集进行深度学习以避免过度拟合。深度神经网络具有许多参数,因此通常如果它们没有足够的数据,它们往往会记住训练集并且在测试集上表现不佳。为了避免没有大数据出现这种现象,我们需要使用特殊技术。在这篇文章中,我将展示我在文章、博客、论坛、Kaggle上发现的一些方法,以便在没有大数据的情况下更好地完成目标。其中许多方法都基于计算机视觉中广泛使用的最佳实践。正则化正则化方法是在机
2、器学习模型内部以不同方式使用的方法,以避免过度拟合,这个方法具有强大的理论背景并且可以以通用的方式解决大多数问题。L1和L2正则化这个方法可能是最古老的,它在许多机器学习模型中使用多年。在这个方法中,我们将权重大小添加到我们试图最小化的模型的损失函数中。这样,模型将尝试使权重变小,并且对模型没有帮助的权重将显着减小到零,并且不会影响模型。这样,我们可以使用更少数量的权重来模拟训练集。有关更多说明,你可以阅读这篇文章。DropoutDropout是另一种较新的正则化方法,训练期间神经网络中的每个节点(神经元)都将被丢弃(权重将被设置为零),这种方式下,网络不能依赖于特定的神经元或神经元的相互作用,必须学习网络不同部分的每个模式。这使得模型专注于推广到新数据的重要模式。提早停止提早停止是一种简单的正则化方法,只需监控验证集性能,如果你发现验证性能不断提高,请停止训练。这种方法在没有大数据的情况下非常重要,因为模型往往在5-10个时期之后甚至更早的时候开始过度拟合。参数数量少如果你没有大型数据集,则应该非常小心设置每层中的参数和神经元数量。此外,像卷积层这样的特殊图层比完全连接的图层具有更少
3、的参数,因此在它们适合你的问题时使用它们非常有用。数据增强数据增强是一种通过以标签不变的方式更改训练数据来创建更多训练数据的方法。在计算机视觉中,许多图像变换用于增强数据集,如翻转、裁剪、缩放、旋转等。这些转换对于图像数据很有用,但不适用于文本,例如翻转像“狗爱我”这样的句子不是一个有效的句子,使用它会使模型学习垃圾。以下是一些文本数据增强方法:同义词替换在这种方法中,我们用他们的同义词替换我们文本中的随机单词,例如,我们将句子“我非常喜欢这部电影”更改为“我非常爱这部电影”,它仍具有相同的含义,可能相同标签。这种方法对我来说不起作用,因为同义词具有非常相似的单词向量,因此模型将两个句子看作几乎相同的句子而不是扩充。方向翻译在这种方法中,我们采用我们的文本,将其翻译成具有机器翻译的中间语言,然后将其翻译成其他语言。该方法在Kaggle毒性评论挑战中成功使用。例如,如果我们将“我非常喜欢这部电影”翻译成俄语,我们会得到“”,当我们翻译成英文时,我们得到“I really like this movie”。反向翻译方法为我们提供了同义词替换,就像第一种方法一样,但它也可以添加或删除单词并解
4、释句子,同时保留相同的含义。文件裁剪新闻文章很长,在查看数据时,有时不需要所有文章来分类文档。这让我想到将文章裁剪为几个子文档作为数据扩充,这样我将获得更多的数据。首先,我尝试从文档中抽取几个句子并创建10个新文档。这就创建了没有句子之间逻辑关系的文档,但我得到了一个糟糕的分类器。我的第二次尝试是将每篇文章分成5个连续句子。这种方法运行得非常好,给了我很好的性能提升。生成对抗性网络GAN是数据科学中最令人兴奋的最新进展之一,它们通常用作图像创建的生成模型。这篇博客文章解释了如何使用GAN进行图像数据的数据增强,但它也可能用于文本。迁移学习迁移学习是指使用来自网络的权重,这些网络是针对你的问题通过另一个问题(通常是大数据集)进行训练的。迁移学习有时被用作某些层的权重初始化,有时也被用作我们不再训练的特征提取器。在计算机视觉中,从预先训练的Imagenet模型开始是解决问题的一种非常常见的做法,但是NLP没有像Imagenet那样可以用于迁移学习的非常大的数据集。预先训练的词向量NLP深度学习架构通常以嵌入层开始,该嵌入层将一个热编码字转换为数字矢量表示。我们可以从头开始训练嵌入层,但我们
《NLP深度学习模型》由会员一***分享,可在线阅读,更多相关《NLP深度学习模型》请在金锄头文库上搜索。
















 5详细设计说明书
5详细设计说明书
2023-05-19 5页
活动需求说明书
2023-05-19 13页
IT项目需求说明书模板
2023-05-19 4页
详细需求说明书-V1.0.doc
2023-05-19 12页
需求分析阶段--需求说明书
2023-05-19 10页
文档型数据库
2023-05-19 4页
数据库-文档
2023-05-19 4页
软件体系结构设计说明书(简要模板)
2023-05-19 4页
MFCbug报告
2023-05-19 1页
详细设计说明书 (2)
2023-05-19 39页