
大数据平台概要设计说明书
32页
1、计算平台概要设计说明书文件编号受控编号版次1.0密级内部公开总页数42附录日期:2013-01-28日期:日期:所有,翻版必究)文件修改记录修改日期修改状态修改页码与条款修改人审核人批准人目录1.引言41.1 编写目的41.2 术语与缩略词51.3对象与X围81.4 参考资料82. 系统总体设计82.1 需求规定 8 数据导入错误!未定义书签。 数据运算错误!未定义书签。 运算结果导出错误!未定义书签。 系统监控错误!未定义书签。 调度功能错误!未定义书签。 自动化安装部署与维护错误!未定义书签。2.2 运行环境82.3 基本设计思路和处理流程 92.4 系统结构10大数据运算系统架构图 10 hadoop 体系各组件之间关系图错误!未定义书签 计算平台系统功能图1 1 系统功能图逻辑说明1 1 计算平台业务流程图错误!未定义书签。2.5 尚未解决的问题123. 模块/功能设计 123.1 计算驱动模块 15设计思路15流程图17处理逻辑 183.2 调度模块13设计思路 13流程图 14处理逻辑 143.3 自动化安装部署模块错误!未定义书签。 设计思路错误!未定义书签。 处理逻辑错
2、误!未定义书签。3.4 调度模块与计算驱动模块交互流程错误!未定义书签。 处理流程图错误!未定义书签。 处理逻辑错误!未定义书签。hadoop 驱动模块调用驱动接口错误!未定义书签。 调度模块接收 hadoop 执行状态接口错误!未定义书签。3.5调度模块与kettle交互流程错误!未定义书签。处理流程图错误!未定义书签。 处理逻辑错误!未定义书签。3.6 对调度任务运行过程进行监控流程错误!未定义书签。处理流程图错误!未定义书签。 处理逻辑错误!未定义书签。3.7对hadoop驱动任务运行过程进行监控流程错误!未定义书签。 处理流程图错误!未定义书签。 处理逻辑错误!未定义书签。3.8对操作系统/应用程序监控流程19处理流程图 19处理逻辑 193.9监控报警模块20设计思路 20流程图 21处理逻辑 214.系统数据结构设计 224.1 数据实体关系图224.2 数据逻辑结构22驱动任务设置表错误!未定义书签。 驱动设置表错误!未定义书签。 驱动任务执行明细表错误!未定义书签。 调度任务表错误!未定义书签。调度步骤表 23 调度步骤执行记录表 24 操作系统监控数据表错误!未定义书
3、签。 应用程序监控数据表错误!未定义书签。 监控系统配置表错误!未定义书签。 业务数据记录表错误!未定义书签。4.3 数据物理结构 315. 安全设计 316. 容错设计 316.1 挽救措施316.2 系统维护设计317. 日志设计 311. 引言1.1编写目的大数据泛指巨量的数据集,因可从中挖掘出有价值的信息而受到重视。华尔街日报将大 数据时代、智能化生产和无线网络革命称为引领未来繁荣的三大技术变革。麦肯锡公司的报 告指出数据是一种生产资料,大数据是下一个创新、竞争、生产力提高的前沿。世界经济论 坛的报告认定大数据为新财富,价值堪比石油。因此,发达国家纷纷将开发利用大数据作为 夺取新一轮竞争制高点的重要抓手。互联网特别是移动互联网的发展,加快了信息化向社会经济各方面、大众日常生活的 渗透。有资料显示,1998年全球网民平均每月使用流量是1MB (兆字节),2000年是10MB, 2003年是100MB,2008年是1GB (1GB等于1024MB),2014年将是10GB。全网流量累 计达到1EB (即10亿GB或1000PB)的时间在2001年是一年,在2004年是一个月,在 2
4、007年是一周,而2013年仅需一天,即一天产生的信息量可刻满1.88亿XDVD光盘。我 国网民数居世界之首,每天产生的数据量也位于世界前列。淘宝每天有超过数千万笔交易, 单日数据产生量超过50TB (1TB等于1000GB),存储量40PB(1PB等于1000TB)。百度公 司目前数据总量接近1000PB,存储网页数量接近1万亿页,每天大约要处理60亿次搜索请 求,几十PB数据。一个8Mbps (兆比特每秒)的摄像头一小时能产生3.6GB数据,一个城 市若安装几十万个交通和安防摄像头,每月产生的数据量将达几十PB。医院也是数据产生 集中的地方。现在,一个病人的CT影像数据量达几十GB,而全国每年门诊人数以数十亿 计,并且他们的信息需要长时间保存。总之,大数据存在于各行各业,一个大数据时代正在 到来。信息爆炸不自今日起,但近年来人们更加感受到大数据的来势迅猛。一方面,网民数量 不断增加,另一方面,以物联网和家电为代表的联网设备数量增长更快。 2007 年全球有 5 亿个设备联网,人均0.1个;2013年全球将有500亿个设备联网,人均70 个。随着宽带化 的发展,人均网络接入带宽和流量
《大数据平台概要设计说明书》由会员桔****分享,可在线阅读,更多相关《大数据平台概要设计说明书》请在金锄头文库上搜索。

内控合规部分练习题

2023年二手房购房正规合同

压力压强单元测试题

2023年四川省阿坝州理县甘堡乡社区工作人员考试模拟题及答案

校园安全大排查、大整治、百日会战工作总结

2023年自考广告文案写作

新教育座谈体会

技术服务协议电子版(九篇)

绿色施工措施
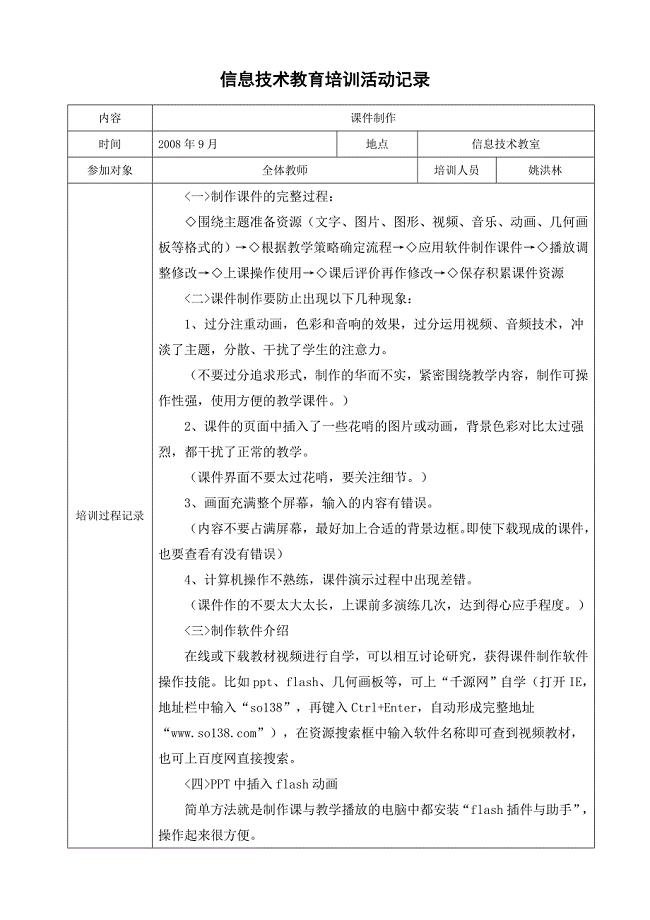
信息技术培训记录

2023物业前台工作总结模板(三篇).doc

皮肤性病学网络课程003

VB课程设计(论文)毕业生信息管理系统

正式的公司承包合同范文

版高考化学二轮复习第1部分专题素能提升练专题8元素及其化合物教案新人教版2

装饰设计工程有限公司员工手册资料

荆州电动工具研发项目招商引资方案

会计从业资格考试核算注意事项
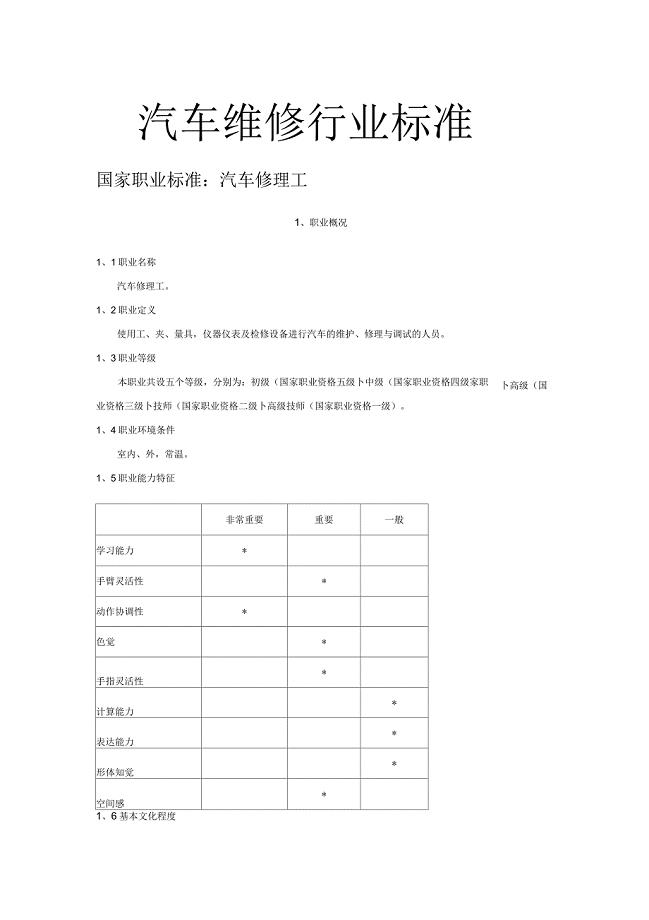
汽车维修行业标准

大专生毕业前自我鉴定
 鲢鱼与鳙鱼
鲢鱼与鳙鱼
2023-07-31 8页
消防安全技术综合能力笔记
2023-03-24 9页
某卷烟污水处理站运维培训内容
2023-02-05 14页
互联网的应用和发展
2022-07-27 2页
电力建设安规考试卷 答案
2023-04-01 12页
写作技巧表达效果
2022-11-02 27页
现代教育技术笔试试题(往年的
2022-08-21 6页
课程理性思考
2022-12-23 9页
MVC6000A双视频流功能操作说明
2023-10-04 9页
尿管注意事项相关
2023-01-01 20页