
使用 Shell 脚本进行 Hadoop Spark 集群的批量安装_光环大数据培训
7页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/使用使用 ShellShell 脚本进行脚本进行 HadoopHadoop SparkSpark 集群的批量安装集群的批量安装_ _光环大数据培训光环大数据培训虽然有一些自动化安装的工具,但是功能越多,越专业的工具,可能也需要越高的学习成本,而我们并非专业运维,但是又必须做这些事情的话,不妨选择用 Shell 脚本来完成集群的安装。当然了,现在也有很多使用 docker 的做法,安装与部署也非常方便。整个过程其实很简单,就是对安装过程中的一些手动操作使用 Shell 脚本进行替代。对脚本比较熟悉的话,应该很容易看懂。推荐一个网站,explainshell , 输入 Shell 命令,它会对命令的各部分进行详细的解释。以下内容虽在 Ubuntu 16.04 试用过,但有些细节可能由于时间因素,难免会有偏差。如有问题,欢迎指正。其他系统要安装的话可适当参照,步骤上大致相同,只是有些细节需要针对性调整。在所有安装步骤中, 最重要的一步是配置最重要的一步是配置 SSH 无密码登录无密码登
2、录 。如果不明白脚本的内容,不要使用我的安装脚本,明白可以抽取部分自用。对安装过程不太熟的话,建议先跟着厦门大学的教程做: Spark2.1.0 入门:Spark 的安装和使用 ,里面涉及了 hadoop 与 Spark 等各种软件的安装,十分详细,对新手很友好。只有对手动安装的整个过程了然于心,自动化安装才能得心应手。为了避免因为用户权限要求输入密码的麻烦,以下所有操作均在 root 用户用户 ,全新系统环境下执行。以下所涉及的所有脚本我都已经放到了 GitHub 上,点击 这里 查看,距离脚本写完已经有一段时间,懒得对代码结构进行优化了:)。如果对某个脚本有疑问,可以自行单独拿出来,在本地进行测试与验证。另外,集群的安装基本上都差不多,这里是陈天奇在 EC2 上安装 yarn 集群的脚本: https:/ ,有兴趣可以看一下。用到主要工具有 rsync 和 expect, rsync 用于同步文件,expect 用于处理需要手动输入的情况。光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/1. 安装必要的软件安装必要的软件比如
3、 Java,openssh-server,expect(用于自动处理一些交互, 只在Master 节点上安装即可),vim 等。在 Master 和 Slave 都要安装这些软件,可以将在配置好 ssh 无密码登录后,将安装脚本同步到各 Slave 进行安装。基本的软件安装基本的软件安装pre-install.sh:#!/usr/bin/env bash# 安装 Vim8,方便修改配置文件 apt install software-properties-commonadd-apt-repository ppa:jonathonf/vimapt updateapt install vim# 安装 git, expect, openssh-serverapt install git expect openssh-server# Install Java8apt install openjdk-8-jre openjdk-8-jdk# Set JAVA_HOMEJAVA_PATH=$(update-alternatives -list java)JAVA_HOME=$JAVA_PATH%/j
4、re/bin*echo “export JAVA_HOME=$JAVA_HOME“ “$HOME/.bashrc“安装安装 Hadoop安装 Hadoop, 大致为 wget 下载 Hadoop,然后解压到 /usr/local/hadoop。install-hadoop.sh:#!/usr/bin/env bashHADOOP_DOWNLOAD_URL=https:/ # hadoop-2.7.3.tar.gzHADOOP_VER=$HADOOP_TAR_GZ%.tar.gz # hadoop-2.7.3if ! -d /usr/local/hadoop ; then ! -f /tmp/$HADOOP_TAR_GZ then ! -f /tmp/$SPARK_TGZ then ! -f /tmp/$HBASE_TAR_GZ chmod 600 /.ssh/authorized_keys“expect “*assword:“ send “$password/n“; exp_continue “yes/no*“ send “yes/n“ ; exp_continue eof exit
《使用 Shell 脚本进行 Hadoop Spark 集群的批量安装_光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《使用 Shell 脚本进行 Hadoop Spark 集群的批量安装_光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
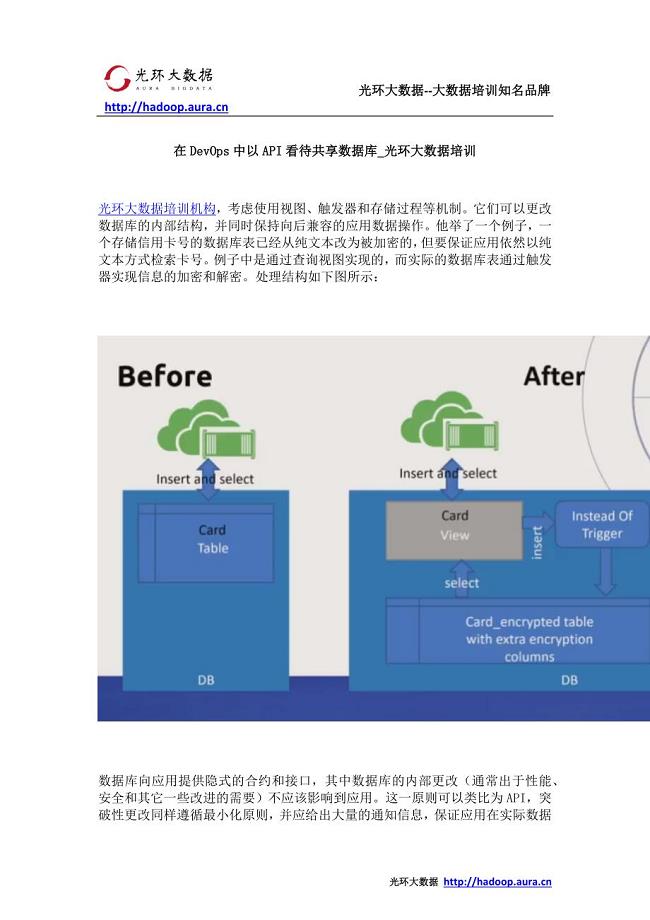
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
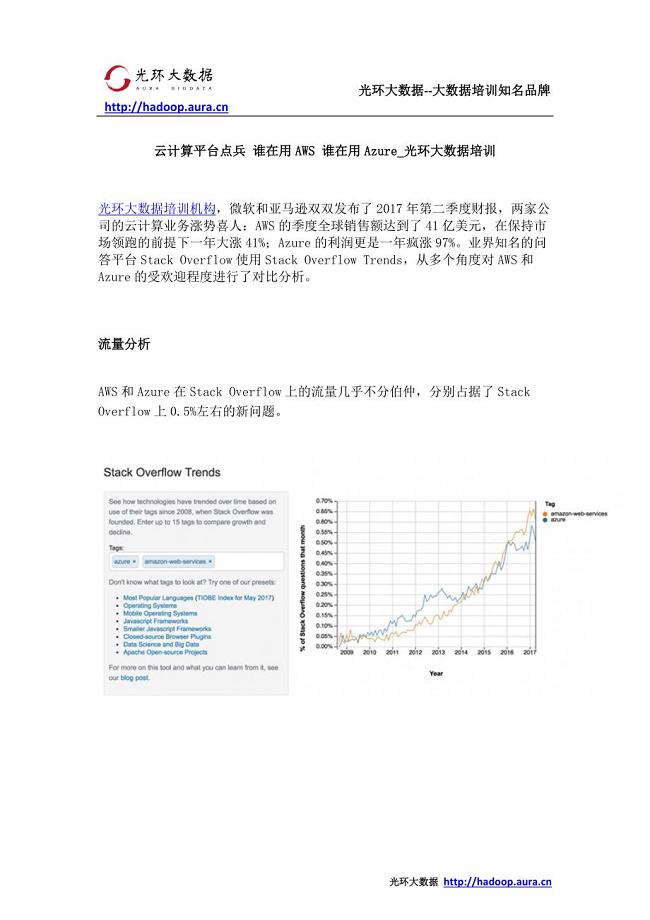
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 南开大学《计算机组成原理》笔记-随堂笔记
南开大学《计算机组成原理》笔记-随堂笔记
2023-09-25 37页
北京林业大学《计算机组成原理》笔记-总结期末复习资料
2023-09-25 10页
《计算机网络》笔记-各章汇总
2023-09-25 33页
《数据结构》笔记-期末复习知识点
2023-09-25 26页
盘点那些高逼格的sql写法
2023-04-03 8页
全程干货:新手小白快速入门sql教程SQL基本书写规则
2023-04-03 4页
经典常用SQL 基础知识数据库与 SQL
2023-04-03 8页
2022年CSP-S第二轮C++真题源码解析1
2023-03-29 10页
2022年CSP-J第二轮C++真题源码解析2
2023-03-22 10页
2022年CSP-J第二轮C++真题源码解析1
2023-03-20 8页