
2018年常见Hadoop面试题及答案_光环大数据培训
8页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/20182018 年常见年常见 HadoopHadoop 面试题及答案面试题及答案_ _光环大数据培训光环大数据培训hadoop 的测试题及答案解析,题目种类挺多,一共有 98 道题,题目难度不大, 对于高手来说,90 分以上才是你的追求。1 单选题1.1 下面哪个程序负责 HDFS 数据存储。a)NameNodeb)Jobtrackerc)Datanoded)secondaryNameNodee)tasktracker答案 C datanode1.2 HDfS 中的 block 默认保存几份?a)3 份b)2 份c)1 份d)不确定答案 A 默认 3 份1.3 下列哪个程序通常与 NameNode 在一个节点启动?a)SecondaryNameNodeb)DataNodec)TaskTracker光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/d)Jobtracker答案 D,此题分析:hadoop 的集群是基于 mas
2、ter/slave 模式,namenode 和 jobtracker 属 于 master,datanode 和 tasktracker 属 于 slave , master 只 有 一 个 , 而 slave 有多个 SecondaryNameNode 内存需求和 NameNode 在一个数量级 上,所以通常 secondary ,NameNode(运行在单独的物理机器上)和 NameNode 运行在不同的机器上。JobTracker 和 TaskTracker,JobTracker 对应于 NameNode,TaskTracker 对应于 DataNode,DataNode 和 NameNode 是针对数 据存放来而言的,JobTracker 和 TaskTracker 是对于 MapReduce 执行而言的, mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索: obclient,JobTracker 与 TaskTracker。JobClient 会在用户端通过 JobClient 类将应用已经配置参数打包成 jar 文件存储到 hdfs,并
3、把路径提交到 Jobtracker,然后由 JobTracker 创建每一 个 Task(即 MapTask 和 ReduceTask)并将它们分发到各个 TaskTracker 服务 中去执行。JobTracker 是一个 master 服务,软件启动之后 JobTracker 接收 Job, 负责调度 Job 的每一个子任务 task 运行于 TaskTracker 上,并监控它们, 如果发现有失败的 task 就重新运行它。一般情况应该把 JobTracker 部署在 单独的机器上。TaskTracker 是运行在多个节点上的 slaver 服务。TaskTracker 主动与 JobTracker 通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需 要运行在 HDFS 的 DataNode 上。1.4 Hadoop 作者a)Martin Fowlerb)Kent Beckc)Doug cutting答案 C Doug cutting1.5 HDFS 默认 Block Sizea)32MB光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/
4、光环大数据光环大数据 http:/b)64MBc)128MB答案:B(因为版本更换较快,这里答案只供参考)1.6 下列哪项通常是集群的最主要瓶颈:a)CPUb)网络c)磁盘 IOd)内存答案:C 磁盘该题解析:首先集群的目的是为了节省成本,用廉价的 pc 机,取代小型机及大型机。 小型机和大型机有什么特点?cpu 处理能力强内存够大。所以集群的瓶颈不可能是 a 和 d网络是一种稀缺资源,但是并不是瓶颈。由于大数据面临海量数据,读写数据都需要 io,然后还要冗余数据, hadoop 一般备 3 份数据,所以 IO 就会打折扣。1.7 关于 SecondaryNameNode 哪项是正确的?a)它是 NameNode 的热备b)它对内存没有要求c)它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间d)SecondaryNameNode 应与 NameNode 部署到一个节点。光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/答案 C2 多选题2.1 下列哪项可以作为集群的管理?a)Puppetb)Pdsh
《2018年常见Hadoop面试题及答案_光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《2018年常见Hadoop面试题及答案_光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
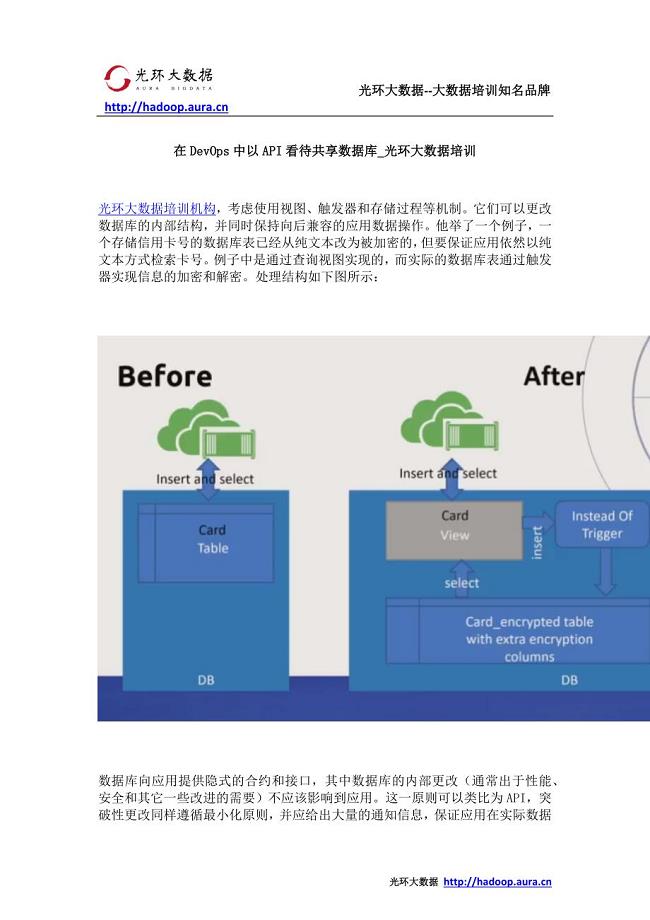
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
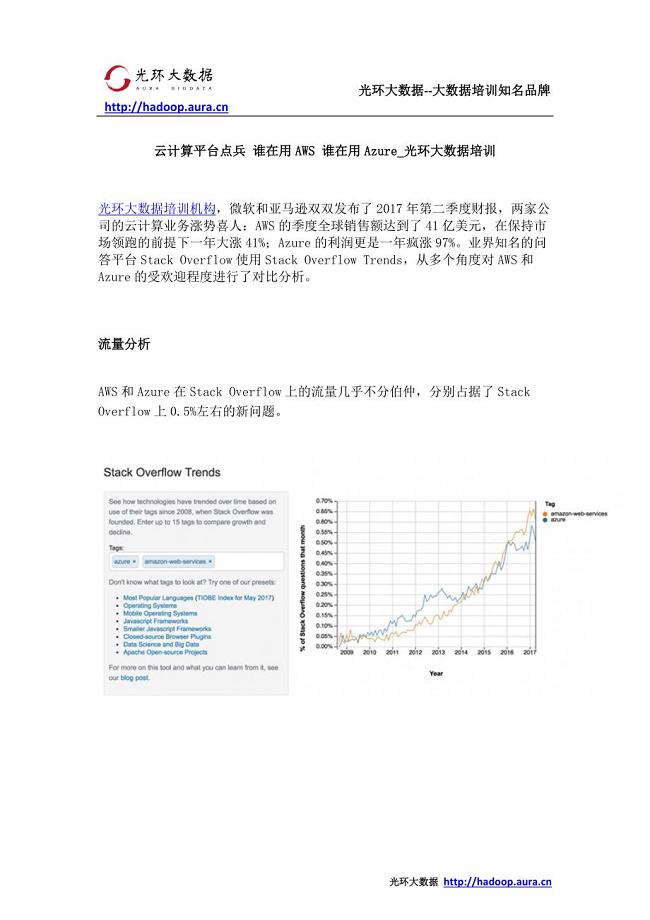
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 用户行为数据分析项目开发计划书
用户行为数据分析项目开发计划书
2020-11-03 46页
最新网络主播合同(协议) .
2020-06-14 4页
主播培训内容 .
2020-06-14 4页
主播签约协议(1) .
2020-06-14 3页
主播签约合同 .
2020-06-14 4页
招募主播合同 .
2020-06-14 5页
主播签约协议 .
2020-06-14 6页
主播管理制度.doc .
2020-06-14 4页
主播薪酬方案 .
2020-06-14 3页
主播基地建设文档 .
2020-06-14 3页