
逻辑回归模型
10页
1、博客园首页逻辑回归模型作者:zgw21cn来源:博客园 发布时间:2008-08-29 17:21阅读:7161次 原文链接 收藏1逻辑回归模型1.1逻辑回归模型考虑具有p个独立变量的向量Ea心),设条件概率= F为根据观测 量相对于某事件发生的概率。逻辑回归模型可表示为P(y = I|x) = Xx) = _l_(1.1)上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。其中E二矗+朋+恥+必帝。如果含有名义变量,则将其变为dummy变量。 一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有(1.2)定义不发生事件的条件概率为r(r - n - j - ft -11 j!4-;(1.3)那么,事件发生与事件不发生的概率之比为严)这个比值称为事件的发生比(the odds of expe rie nci ng an eve nt),简称为odds。因为 Ovpvl,故odds0。对odds取对数,即得到线性函数,(1.5)如J:-爲: 2 為心“哄-p 1歹:1.2极大似然函数假设有n个观测样本,观测值分别为h入设戸二=1丨丙)为给定条件下得到戸=1的概率。在
2、同样条件下得到戸=的条件概率为尸=丨吗)=1-凤。于是, 得到一个观测值的概率为(1.6)因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。0) = 1斑界1-牴町严(1.7)上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估 计。于是,最大似然估计的关键就是求出参数弘久用F,使上式取得最大值。对上述函数求对数(1.8)上式称为对数似然函数。为了估计能使取得最大的参数弘况用$的值。对此函数求导,得到P+1个似然方程。13仇知-弋叶”严严(1.9)L*1=1-,j = 1,2,.,p.上式称为似然方程。为了解上述非线性方程,应用牛顿一拉斐森(Newto n-Raphso n)方法 进行迭代求解。1.3牛顿一拉斐森迭代法对求二阶偏导数,即Hessian矩阵为-迟沪內(1-馅)2-1(1.10):-乞咛丸(1-坯)2-1如果写成矩阵形式,以H表示Hessian矩阵,X表示(1.11)(I(1.12)则H = g。再令 然方程的矩阵形式。得牛顿迭代法的形式为1忑11%尹1 一汀11也1% 九一花_1耳1备兔口一疳(注:前一个矩阵需转置),即似(“3)注
3、意到上式中矩阵H为对称正定的,求解H1U即为求解线性方程HX = U中的矩阵X。对H进行cholesky分解。最大似然估计的渐近方差(asymptotic va ria nee )和协方差(cova ria nee)可以由信息矩阵(information matrix)的逆矩阵估计出来。而信息矩阵实际上是(闻二阶导数的负值, 表示为。炖毘。估计值的方差和协方差表示为沁(阶厂,也就是说,估计值炖的 方差为矩阵I的逆矩阵的对角线上的值,而估计值冋和煜的协方差为除了对角线以外的 值。然而在多数情况,我们将使用估计值的标准方差,表示为for j = 0,1,2,,p (1.14)2 .显著性检验下面讨论在逻辑回归模型中自变量心是否与反应变量显著相关的显著性检验。零假设丹o :负=0 (表示自变量忑对事件发生可能性无影响作用)。如果零假设被拒绝,说明事件发生可能性依赖于忑的变化。2.1 Wald test对回归系数进行显著性检验时,通常使用Wald检验,其公式为 貶“齐磁(玄)(2.)其中,能为的标准误差。这个单变量Wald统计量服从自由度等于1的/分布。 如果需要检验假设凤:煜=屁=M =0,
4、计算统计量册=釦验费)(2.2) 其中,庐为去掉矗所在的行和列的估计值,相应地,敬的为去掉储所在的行和列的标 准误差。这里,Wald统计量服从自由度等于p的,分布。如果将上式写成矩阵形式,有 琢=(qEnq仙(3)qt(q3)(2.3)0 1 0Q =矩阵Q是第一列为零的一常数矩阵。例如,如果检验煜二炖,则 L 1。然而当回归系数的绝对值很大时,这一系数的估计标准误就会膨胀,于是会导致Wald 统计值变得很小,以致第二类错误的概率增加。也就是说,在实际上会导致应该拒绝零假设 时却未能拒绝。所以当发现回归系数的绝对值很大时,就不再用Wald统计值来检验零假设, 而应该使用似然比检验来代替。2.2 似然比(Likelihood ratio test)检验_ _ 2在一个模型里面,含有变量丙与不含变量丙的对数似然值乘以-2的结果之差,服从尸分布。这一检验统计量称为似然比(likelihood ratio),用式子表示为G=-21n(不含再似然 含有吗似然(2.4)计算似然值采用公式(1.8)。倘若需要检验假设丹:矗=色=爲=0,计算统计量-Til.:; J :J| _Ti::; | ,1 :
《逻辑回归模型》由会员夏**分享,可在线阅读,更多相关《逻辑回归模型》请在金锄头文库上搜索。

财务部门个人工作总结范本(2篇).doc

就业培训班开班主持词.doc

4某大学教学楼玻璃幕墙施工方案

便道施工作业指导书综述(DOC 11页)

房地产经纪人个人工作计划书范文(16篇)

编导的自我介绍

《燕子专列》读后感

2022追梦环保人演讲稿范文(5篇)
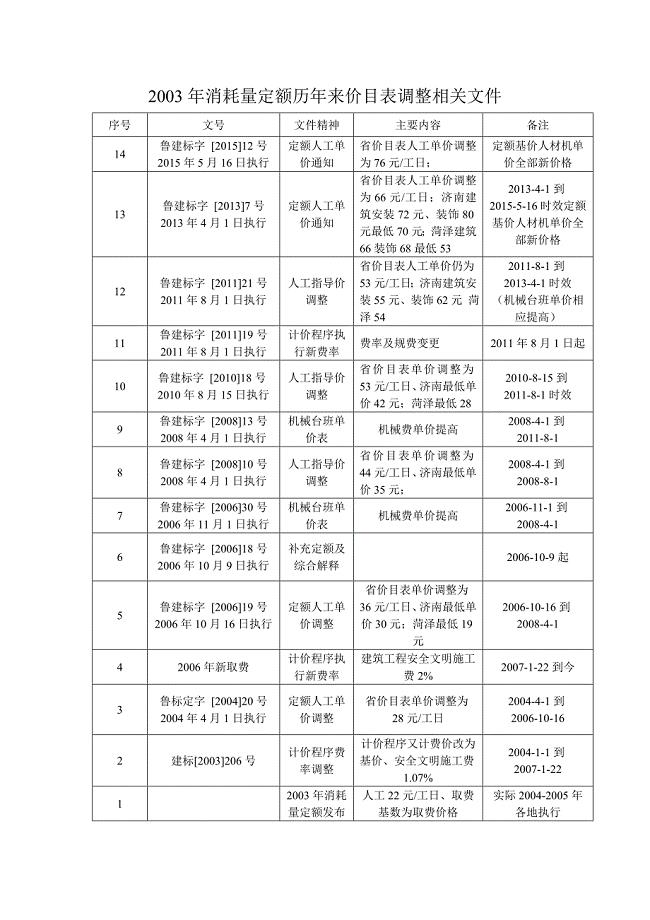
定额价目表及取费变化

MCGS软件与MCS51单片机多机通信的几种方法

三年级数学下册期末试卷 (I)

2023-2024学年度新教师培训工作计划模板(3篇).doc

困难申请书范文

福建省晋江市永春县第一中学2016-2017学年高一化学上学期期末考试试题

幼儿园毕业典礼家长致辞稿1

2014-2015学年高一物理人教版必修一教案:1.2 时间和位移

小学低年级一步计算应用题归纳总结

2022年小学后勤处工作总结

小学综合实践活动四年级下册《巧手做风筝》教学设计(共37页)

2023年湖北省黄冈市黄州区陈策楼镇浒子口村社区工作人员考试模拟试题及答案
 ChinaTT积分制度说明
ChinaTT积分制度说明
2022-09-11 4页
c语言学习笔记(数组、函数)
2023-12-04 53页
MCGS软件与MCS51单片机多机通信的几种方法
2023-08-17 14页
项目管理工作的改进建议
2023-09-10 5页
[双重预防机制实施方案]预防职业病实施方案
2023-06-02 6页
ERP系统调研问卷(进销存
2023-08-22 31页
牛津英语Unit3词组
2023-05-06 2页
00398《学前教育原理》复习资料
2022-08-30 23页
回转窑瓦温高原因及处理方案
2023-12-12 8页
人类学的语言定位
2023-01-05 2页