
主题模型lda
49页
1、主题模型LDA,北京10月机器学习班 邹博 2014年11月16日,2/49,主要内容和目标,共轭先验分布 Dirichlet分布 unigram model LDA Gibbs采样算法,3/49,随机变量的分布,4/49,思考,尝试计算X(k)落在区间x,x+x的概率:,5/49,划分为3段,6/49,事件E1的概率,7/49,事件E2:假设有2个数落在区间x,x+x,8/49,只需要考虑1个点落在区间x,x+x,9/49,X(k)的概率密度函数,10/49,补充:函数,函数是阶乘在实数上的推广,11/49,利用函数,12/49,增加观测数据,13/49,思考过程,14/49,思考过程,15/49,共轭分布,注:上式中的加号“+”,并不代表实际的数学公式是相加,事实上,实际计算过程是相乘的。,16/49,Beta分布的概率密度曲线,17/49,18/49,直接推广到Dirichlet分布,19/49,贝叶斯参数估计的思考过程,20/49,共轭先验分布,在贝叶斯概率理论中,如果后验概率P(|x)和先验概率p()满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做
2、似然函数的共轭先验分布。 In Bayesian probability theory, if the posterior distributions p(|x) are in the same family as the prior probability distribution p(), the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood function.,21/49,共轭先验分布的提出,某观测数据服从概率分布P()时, 当观测到新的X数据时,有如下问题: 可否根据新观测数据X,更新参数 根据新观测数据可以在多大程度上改变参数 + 当重新估计的时候,给出新参数值的新概率分布。即:P(|x),22/49,分析,根据贝叶斯法则 P(x|)表示以预估为参数的x概率分布,可以直接求得。P()是已有原始的概率分布。 方案:选取P(x|)的共轭先验作为P()的分布,这样,P(x|)乘以P()然
3、后归一化结果后其形式和P()的形式一样。,23/49,举例说明,投掷一个非均匀硬币,可以使用参数为的伯努利模型,为硬币为正面的概率,那么结果x的分布形式为: 其共轭先验为beta分布,具有两个参数和,称为超参数(hyperparameters)。简单解释就是,这两个参数决定了参数。 Beta分布形式为,24/49,先验概率和后验概率的关系,计算后验概率 归一化这个等式后会得到另一个Beta分布,即:伯努利分布的共轭先验是Beta分布。,25/49,伪计数,可以发现,在后验概率的最终表达式中,参数和和x,1-x一起作为参数的指数。而这个指数的实践意义是:投币过程中,正面朝上的次数。因此, 和常常被称作“伪计数”。,26/49,推广,二项分布多项分布 Beta分布Dirichlet分布,27/49,Dirichlet分布的定义,28/49,Dirichlet分布的分析,是参数,共K个 定义在x1,x2xK-1维上 x1+x2+xK-1+xK=1 x1,x2xK-10 定义在(K-1)维的单纯形上,其他区域的概率密度为0 的取值对Dir(p| )有什么影响?,29/49,Symmetric
4、Dirichlet distribution,A very common special case is the symmetric Dirichlet distribution, where all of the elements making up the parameter vector have the same value. Symmetric Dirichlet distributions are often used when a Dirichlet prior is called for, since there typically is no prior knowledge favoring one component over another. Since all elements of the parameter vector have the same value, the distribution alternatively can be parametrized by a single scalar value , called the concentrat
《主题模型lda》由会员suns****4568分享,可在线阅读,更多相关《主题模型lda》请在金锄头文库上搜索。

土地管理与地籍测量---第八章界址点测量
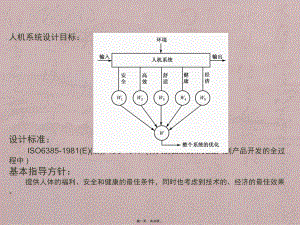
人机工程学案例分析(2)

工程安全培训_201303

第9章房地产投资决策分析

第2章房地产经纪制度

ACM程序设计-东北林业大学acm05

《亲爱的汉修先生》读书交流会

中原_深圳新世界尖岗山项目市场汇报_40P_2012年_别墅_项目分析_量价走势

五年级数学质量分析演示文稿

人工智能小镇-智慧小镇建设20180525

景观基本知识及发展历程

建设工程信息管理(2)

机电驱动技术第二章步进驱动技术
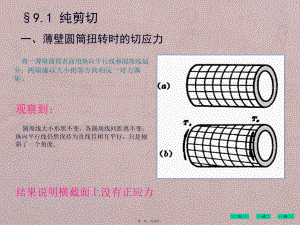
工程力学-第9章圆轴扭转时的应力变形分析与强度刚度设计

第一章第二节幼儿园文化环境建设的原则

第一章检测技术的基础知识

第一章__现代表面工程技术

第六章钢结构工程

第9节项目试运行管理

班主任工作经验交流课件(4)
 优质护理培训课件
优质护理培训课件
2023-12-11 28页
怎么练好护理操作课件
2023-12-11 28页
面瘫的治疗与护理课件
2023-12-11 27页
脑卒中患者护理课件模板
2023-12-11 31页
护理反向交班课件
2023-12-11 27页
护理案例比赛课件题目
2023-12-11 27页
医院icu护理课件
2023-12-11 33页
乙肝的护理课件
2023-12-11 28页
中药坐浴护理课件
2023-12-11 26页
口腔护理课件题目
2023-12-11 29页