
聚类分析学习总结.
9页
1、聚类分析学习体会聚类分析是多元统计分析中研究“物以类聚”的一种方法,用于对事物的类别尚不清 楚,甚至在事前连总共有几类都不能确定的情况下进行分类的场合。聚类分析主要目的是研究事物的分类,而不同于判别分析。在判别分析中必须事先知 道各种判别的类型和数目,并且要有一批来自各判别类型的样本,才能建立判别函数来对 未知属性的样本进行判别和归类。若对一批样品划分的类型和分类的数目事先并不知道, 这时对数据的分类就需借助聚类分析方法来解决。聚类分析把分类对象按一定规则分成组或类,这些组或类不是事先给定的而是根据数 据特征而定的。在一个给定的类里的这些对象在某种意义上倾向于彼此相似,而在不同类 里的这些对象倾向于不相似。1聚类统计量在对样品(变量)进行分类时,样品(变量)之间的相似性是怎么度量?通常有三种 相似性度量一一距离、匹配系数和相似系数。距离和匹配系数常用来度量样品之间的相似 性,相似系数常用来变量之间的相似性。样品之间的距离和相似系数有着各种不同的定 义,而这些定义与变量的类型有着非常密切的关系。通常变量按取值的不同可以分为:1. 定量变量:变量用连续的量来表示,例如长度、重量、速度、人口
2、等,又称为间 隔尺度变量。2. 定性变量:并不是数量上有变化,而只是性质上有差异。定性变量还可以再分 为:有序尺度变量:变量不是用明确的数量表示,而是用等级表示,例如文化程度分为文盲、小学、中学、大学等。名义尺度变量:变量用一些类表示,这些类之间既无等级关系,也无数量关系,例如职业分为工人、教师、干部、农民等。下面主要讨论具有定量变量的样品聚类分析,描述样品间的亲疏程度最常用的是距 离。1.1. 距离1. 数据矩阵设*为第i个样品的第j个指标,数据矩阵如下表品就是Rp中的n个点。在Rp中需定义某种距离,第1个样品与第j个样品之间的距离记为q,在聚类过程中,相距较近的点倾向于归为一类,相距较远的点应归属不同的类。所 定义的距离q一般应满足如下四个条件:(l) q 0,对一切i, j ;且d(x,XJ0当且仅当x Xjdjdji,对一切 i, j ; d ijd ikdkj,对一切 L j,k2. 定量变量的常用的距离对于定量变量,常用的距离有以下几种:闵科夫斯基(Minkowski)距离Pdj(q) XkXjkqq这里q为某一自然数。闵科夫斯基距离有以下三种特殊形式:1) 当q 1时,d
3、j(1) XikXjk称为绝对值距离,常被形象地称为“城市k 1街区”距离;p X2 2) 当q 2时,q(2) XjkX.k2,称为欧氏距离,这是聚类分析中最k 1常用的距离;3) 当q时,d.( ) max XjkXjk,称为切比雪夫距离。J1 k pJq(q)在实际中用得很多,但是有一些缺点,一方面距离的大小与各指标的观测单位 有关,另一方面它没有考虑指标间的相关性。当各指标的测量值相差悬殊时,应先对数据标准化,然后用标准化后的数据计算距 离;最常用的标准化处理是:XX令 XSjj1n其中Xj - X.为第j个变量的样本均值,Sj n 1 i 1ni 1-(Xj Xj)2为第j个变量的样本方差。兰氏(Lance和Williams )距离当 Xj0( i 1,2,n; j 1,2,第i个样品与第j个样品间的兰氏距离为dj(L)p XikXjkk 1Xik Xjk这个距离与各变量的单位无关,但没有考虑指标间的相关性。马氏距离(Mahalanobis)距离第i个样品与第j个样品间的马氏距离为dj(M) .(XiXj)S1(XiXj)其中X X .X , , X ), X.(X.,X夕X
4、 ), S为样品协方差矩阵。/、 Ii ( iV l2 ip , j j V j2 jp / / J J-使用马氏距离的好处是考虑到了各变量之间的相关性,并且与各变量的单位无关;但马氏距离有一个很大的缺陷,就是S难确定。由于聚类是一个动态过程,故S随聚类过程而变化,那么同样的两个样品之间的距离可能也会随之而变化,这不符和聚类 的基本要求。因此,在实际聚类分析中,马氏距离不是理想的距离。斜交空间距离第i个样品与第j个样品间的斜交空间距离定义为d 牙1 &:X)(X X.rijik jkii jj kiJP killd 其中g是变量xk与变量X间的相关系数。当p个变量互不相关时,djj即斜交空j间距离退化为欧氏距离(除相差一个常数倍外)。P以上几种距离的定义均要求样品的变量是定量变量,如果使用的是定性变量,则有 相应的定义距离的方法。3. 定性变量的距离下例只是对名义尺度变量的一种距离定义。例1某高校举办一个培训班,从学员的资料中得到这样6个变量:性别(*)取值为 男和女;外语语种(X2)取值为英、日和俄;专业(X3)取值为统计、会计和金融;职 业(X4)取值为教师和非教师;居住处(X5)
《聚类分析学习总结.》由会员re****.1分享,可在线阅读,更多相关《聚类分析学习总结.》请在金锄头文库上搜索。

审计助理毕业实习报告范本2022投稿合集.doc
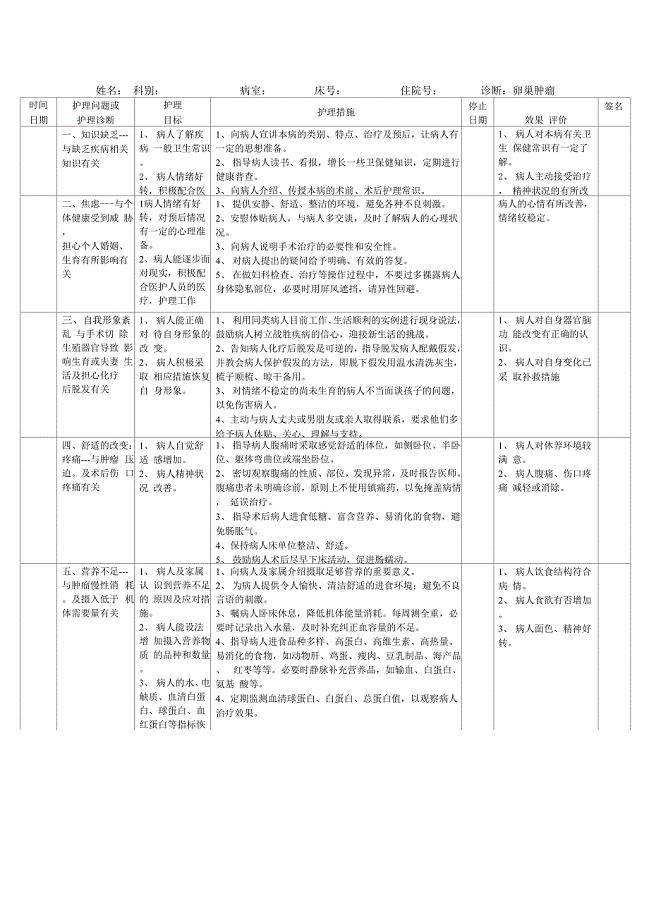
妇产科护理计划
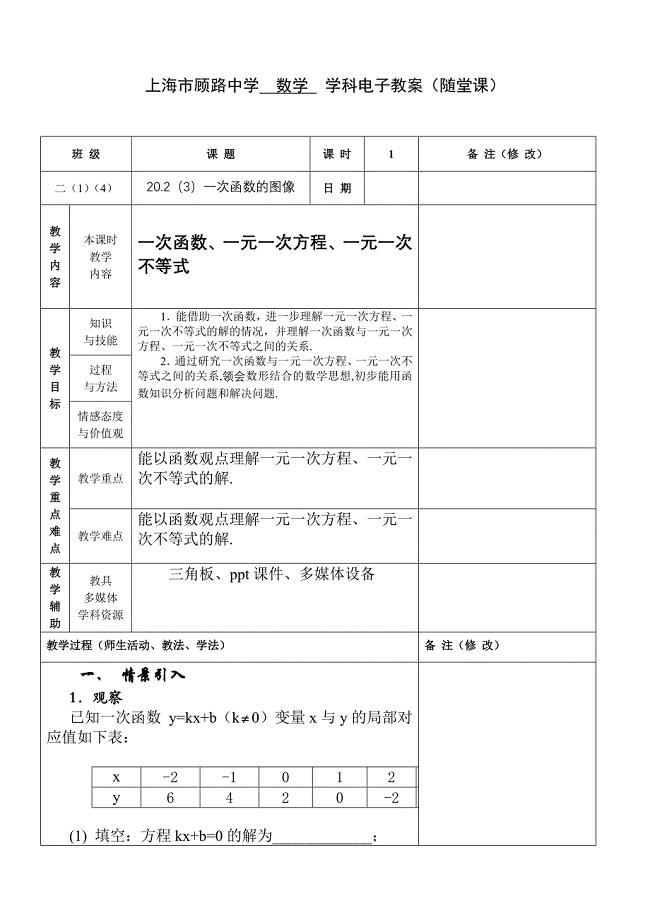
20.2(3)一次函数的图像

昆虫记蟋蟀读后感精选六篇

安庆水处理解决方案项目申请报告

计算机信息安全专业自荐信

大学生社团才艺晚会策划书

保育员个人培训工作计划标准范文(五篇).doc

送给朋友母亲节祝福语

练好文言文基本功-熟记断句口诀

三年级数学教案住新房

有关小学生的调查汇报生存调查汇报四篇

平顶山关于成立汽车轴承公司可行性报告【模板范本】

法人授权委托书

合租房合同书律师版(七篇).doc

2019-2020学年高中数学第二章函数4二次函数性质的再研究4.1二次函数的图像练习北师大版必修1

初三物理试题及答案

写给男朋友的检讨书范文

2022年安全行为观察总结

英语最基本交流100句
 产业园区创新主体集聚公司内部控制制度
产业园区创新主体集聚公司内部控制制度
2022-10-14 89页
半硬质阻燃型塑料管暗敷设工程[详细]
2024-02-12 4页
授权托付书15篇
2022-08-16 18页
昆虫记蟋蟀读后感精选六篇
2023-08-27 6页
孟子的性善论与荀子的性恶论区别
2024-01-22 4页
在小说阅读中培养学生的批判性思维
2023-08-23 2页
货物签收单2010
2024-02-09 1页
iphone、ipad资料库、备份转移存储位置的方法
2022-12-02 10页
物业小区消防安全工作计划范文
2022-09-25 24页
无固定期限劳动合同模板集合十篇
2023-11-20 44页