
数据仓库与 OLTP 性能管理_光环大数据培训
7页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/数据仓库与数据仓库与 OLTPOLTP 性能管理性能管理_ _光环大数据培训光环大数据培训光环大数据培训机构,DB2 数据仓库环境中的性能管理与基于 DB2 的 OLTP 应 用程序中的监视和调优很不一样。重要的差异包括:单独的单独的 SQLSQL 语句与事务。语句与事务。在 OLTP 环境中,典型的事务包含多个 SQL 语句, 常常可以在一秒内完成。对于 BI 应用程序,“事务”(用户与系统的一次交 互)可能只执行一个 SQL 语句,但是这个语句可能要运行几分钟,甚至一小时 以上,而且这不被认为是 “慢”。如果一个报告原本要运行 10 小时,而现在 可以在一小时内完成,用户会非常高兴。事实和维。事实和维。用于 OLTP 工作的 DB2 数据库很可能采用传统 3NF 设计(或相近 的设计)。而数据仓库数据库设计常常采用维,按照 “星型模式” 组织相关 的表(位于中心的 “事实” 表和相关联的维表)。连续与夜间数据库更新。连续与夜间数据库更新。对于 OLTP 应用程序,往往随时进行
2、数据库更新。对 于 BI 应用程序,尽管对接近实时地更新数据库值的兴趣正在增长,但是数据 仓库数据库通常在夜间进行更新,常常要执行大量提取、转换和装载 (ETL) 操 作。在 ETL 处理期间通常不能进行查询访问,这要求必须及时地完成数据库更 新过程。小结果集与大结果集。小结果集与大结果集。OLTP 事务程序中的 SELECT 语句通常只获取少量数据库 行(常常只有一两行)。数据仓库查询(尤其是那些用来生成报告或在线分析 处理多维数据集的查询)可能返回成千上万(甚至上百万)行。光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/复杂查询与简单查询。复杂查询与简单查询。OLTP 事务程序中的 SELECT 语句常常非常简单:只访问一两个表,很少或不需要构建动态表,很少或不需要动态地转换数据值或类型。 与 BI 应用程序相关的查询可能长达几页,包含十几个甚至更多表的联结,包 含嵌套的或通用的表表达式、递归的 SQL、数据值不同的 CASE 表达式和数据 类型转换(通过 CAST 声明或标量函数)。不得不使用的不得不使用的 SQLSQL
3、与自己编写(至少是自己检查过)的与自己编写(至少是自己检查过)的 SQLSQL 。在数据仓库环 境中,常常由报告或 OLAP 工具生成 SQL,您在执行它之前没有机会修改它。 您要负责设置适当的 DB2 环境,让这些查询能够良好地运行。总的来说,DB2 专业人员要通过两方面的工作帮助实现良好的数据仓库性能:设置 DB2 环境,让查询有机会良好地运行。有效地调整运行时间过长的查询(无论是否出色地完成了第一个任务)。本文主要关注 DB2 环境的设置。在下一期中,将讨论数据仓库 SQL 语句的调 优。适当地设置适当地设置 DB2DB2 环境环境建立有助于提高查询性能的 DB2 数据仓库环境涉及系统级和应用程序级措施。 对于 DB2 系统,应该注意以下方面:光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/使用使用 6464 位寻址。位寻址。更大的 DB2 缓冲区池总是有助于提高性能,但是它们对于 I/O 密集型的数据仓库工作负载尤其有用。许多有经验的 DB2 专业人员已经习 惯了 2GB(大型机)或 4GB(Linux/Unix/Win
4、dows)的内存空间限制,他们要 花点儿时间适应 64 位程序。当前的服务器拥有极大的内存:在 IBM System z 大型机、System p 服务器(AIX 或 Linux)或 System x 服务器(Windows 或 Linux)上,可以有 1TB 甚至更多的系统内存。这些平台上的 DB2 支持至少 1TB 的缓冲区池配置。如果服务器有大量内存资源,就应该好好利用 DB2 缓冲区池。我曾经见过在有 40GB 系统内存的服务器上运行的 DB2 只配置了 800MB 的缓冲区池。这太小了: 在这种情况下(至少)10-20GB 要适合得多。请记住,随着缓冲区池大小的增加,磁盘读 I/O 活动的数量会减少。还可以让 DB2 自己选择缓冲区池大小。自动内存管理是 DB2 9 for LUW 中非常受欢迎的 特性,现在 DB2 9 for z/OS(与 z/OS Workload Manager 协作)可以通过 ALTER BUFFERPOOL 命令的 AUTOSIZE(YES) 选项管理缓冲区池大小。利用查询并行性。利用查询并行性。DB2 可以把处理查询所需的工作分割为片段,并行地执
《数据仓库与 OLTP 性能管理_光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《数据仓库与 OLTP 性能管理_光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
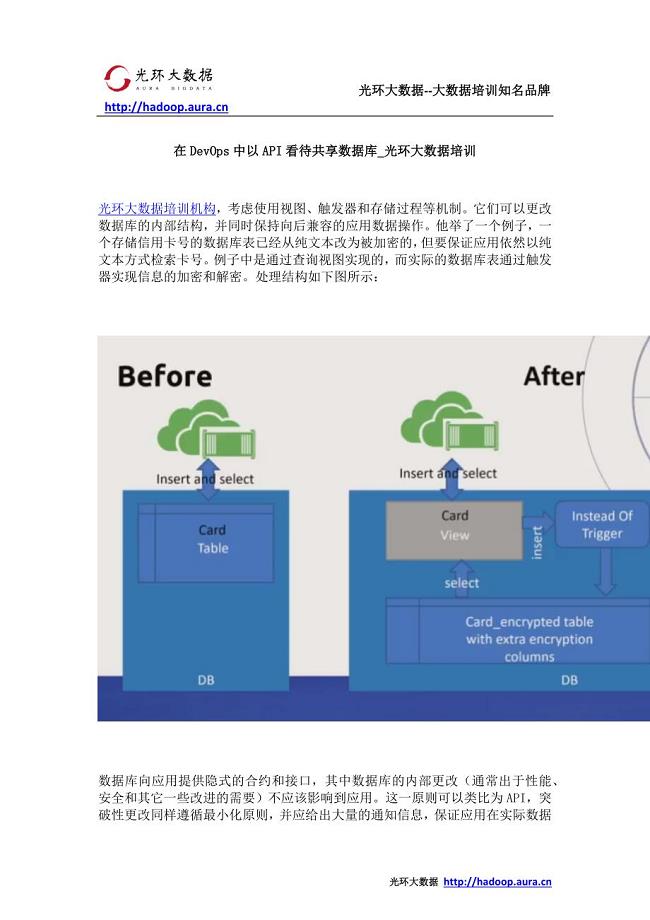
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
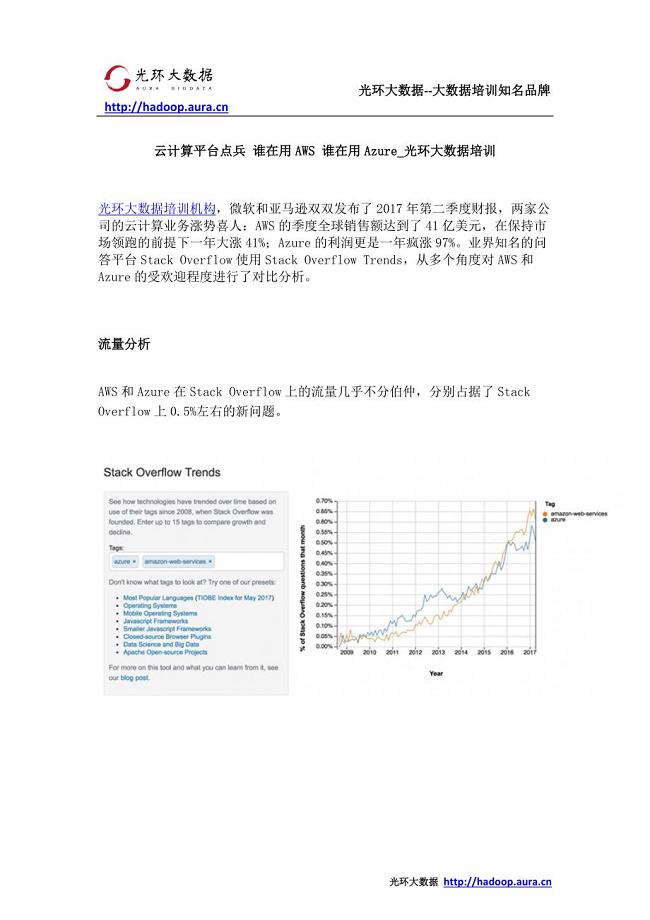
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 南开大学《计算机组成原理》笔记-随堂笔记
南开大学《计算机组成原理》笔记-随堂笔记
2023-09-25 37页
北京林业大学《计算机组成原理》笔记-总结期末复习资料
2023-09-25 10页
《计算机网络》笔记-各章汇总
2023-09-25 33页
《数据结构》笔记-期末复习知识点
2023-09-25 26页
盘点那些高逼格的sql写法
2023-04-03 8页
全程干货:新手小白快速入门sql教程SQL基本书写规则
2023-04-03 4页
经典常用SQL 基础知识数据库与 SQL
2023-04-03 8页
2022年CSP-S第二轮C++真题源码解析1
2023-03-29 10页
2022年CSP-J第二轮C++真题源码解析2
2023-03-22 10页
2022年CSP-J第二轮C++真题源码解析1
2023-03-20 8页