
Spark怎样超越Hadoop MapReduce _光环大数据培训
5页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/SparkSpark 怎样超越怎样超越 HadoopHadoop MapReduceMapReduce _ _光环大数据培训光环大数据培训光环大数据培训光环大数据培训认为,和 hadoop 一样,Spark 提供了一个 Map/Reduce API(分布式计算)和分布式存储。二者主要的不同点是,Spark 在集群的内存中 保存数据,而 Hadoop 在集群的磁盘中存储数据。本文选自SparkGraphX 实战。大数据对一些数据科学团队来说是 主要的挑战,因为在要求的可扩展性方 面单机没有能力和容量来运行大规模数据处 理。此外,即使专为大数据设计的 系统,如 Hadoop,由于一些数据的属性问题也很难有效地处理图数据,我们将 在本章的其他部分看到这方面的内容。Apache Spark 与 Hadoop 类似,数据分布式存储在服务器的集群或者是 “节点”上。 不同的是,Spark 将数据保存在内存(RAM)中,Hadoop 把数据保 存在磁盘(机械 硬盘或者 SSD 固态硬盘)中。定
2、义 :在图和集群计算方面,“节点”这个词有两种截然不同的意思。 图数据由顶点和边组成,在这里“节点”与顶点的意思相近。在集群计算 方面, 组成集群的物理机器也被称为“节点”。为避免混淆,我们称图的 节点为顶点, 这也是 Spark 中的专有名词。而本书中的“节点”这个词我 们严格定义为集 群中的单个物理计算节点。大数据因为数据量大单机无法处理。Hadoop 和 Spark 都是把数据分布在 集群节点上的分 布式框架中。Spark 把分布式数据集存放在内存中,所以比 Hadoop 把数据存放在磁盘中 处理速度要快很多。除了将要计算的数据保存的位置不同(内存和磁盘),Spark 的 API 比 Hadoop 的 Map/Reduce API 更容易使用。Spark 使用简洁且表达力较好的 Scala 作为原生编程语言,写 Hadoop Map/Reduce 的 Java 代码行数与写 Spark 的 Scala 的代码行的数 量比一般是 10:1。虽然本书主要使用 Scala,但是你对 Scala 不熟悉也不用担心,我们在第 3 章提 供了快速入门,包括怪异、晦涩和简练的 Scala 语法
3、。进一步熟悉 Java、C+、C#、 Python 等至少一门编程语言是必要的。模糊的大数据定义模糊的大数据定义光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/现在的“大数据”概念已经被很大程度地夸大了。大数据的概念可以追溯 到 Google 在 2003 年发表的 Google 文件系统的论文和 2004 年发表的 Map/Reduce 论文。大数据这个术语有多种不同的定义,并且有些定义已经失去了大数据所应 有的意 义。但是简单的核心且至关重要的意义是:大数据是因数据本身太大, 单机无法处理。数据量已经呈爆炸性增长。数据来自网站的点击、服务器日志和带有传感 器的 硬件等,这些称为数据源。有些数据是图数据(graph data),意味着由边 和顶点组成, 如一些协作类网站(属于“Web 2.0”的社交媒体的一种)。大的 图数据集实际上是 众包的,例如知识互相连接的 Wikipedia、Facebook 的朋 友数据、LinkedIn 的连接数 据,或者 Twitter 的粉丝数据。HadoopHadoop :SparkSpark
4、 之前的世界之前的世界在讨论 Spark 之前,我们总结一下 Hadoop 是如何解决大数据问题的,因 为 Spark 是建立在下面将要描述的核心 Hadoop 概念之上的。Hadoop 提供了在集群机器中实现容错、并行处理的框架。Hadoop 有两个 关键 能力 :HDFSHDFS分布式存储分布式存储MapReduceMapReduce分布式计算分布式计算HDFS 提供了分布式、容错存储。NameNode 把单个大文件分割成小块,典 型 的块大小是 64MB 或 128MB。这些小块文件被分散在集群中的不同机器上。 容错性 是将每个文件的小块复制到一定数量的机器节点上(默认复制到 3 个不 同节点, 下图中为了表示方便,将复制数设置为 2)。假如一个机器节点失效, 致使这个机器上的 所有文件块不可用,但其他机器节点可以提供缺失的文件块。 这是 Hadoop 架构的 关键理念 :机器出故障是正常运作的一部分。三个分布式数据块通过 Hadoop 分布式文件系统(HDFS)保持两个副本。MapReduce 是提供并行和分布式计算的 Hadoop 并行处理框架,如下图 。MapReduce
《Spark怎样超越Hadoop MapReduce _光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《Spark怎样超越Hadoop MapReduce _光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
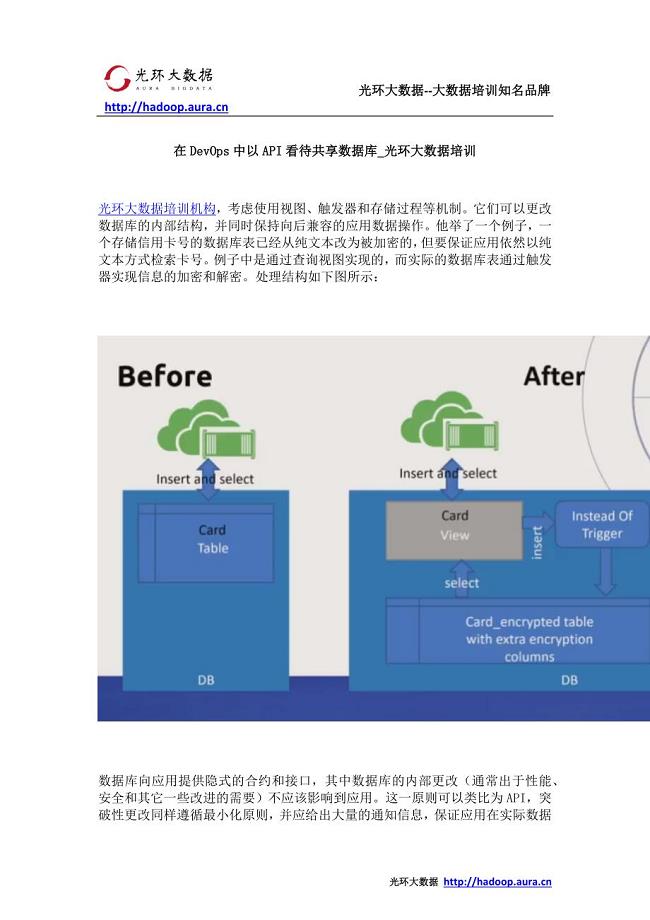
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
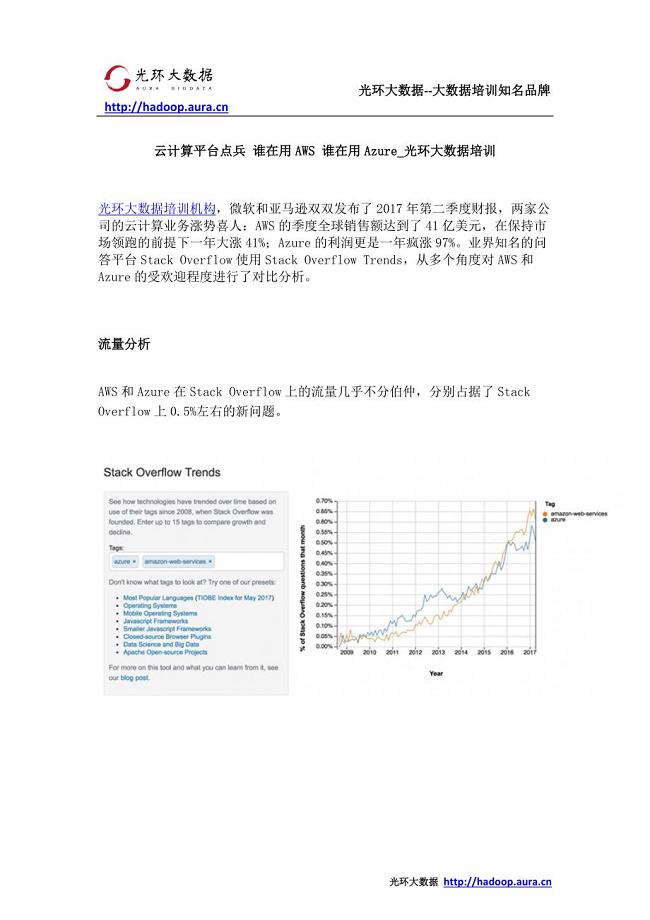
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 南开大学《计算机组成原理》笔记-随堂笔记
南开大学《计算机组成原理》笔记-随堂笔记
2023-09-25 37页
北京林业大学《计算机组成原理》笔记-总结期末复习资料
2023-09-25 10页
《计算机网络》笔记-各章汇总
2023-09-25 33页
《数据结构》笔记-期末复习知识点
2023-09-25 26页
盘点那些高逼格的sql写法
2023-04-03 8页
全程干货:新手小白快速入门sql教程SQL基本书写规则
2023-04-03 4页
经典常用SQL 基础知识数据库与 SQL
2023-04-03 8页
2022年CSP-S第二轮C++真题源码解析1
2023-03-29 10页
2022年CSP-J第二轮C++真题源码解析2
2023-03-22 10页
2022年CSP-J第二轮C++真题源码解析1
2023-03-20 8页