
QJM 核心源代码解读 Hadoop namenode 高可用性分析_光环大数据培训
11页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/QJMQJM 核心源代码解读核心源代码解读 HadoopHadoop namenodenamenode 高可用性分析高可用性分析_ _光环大数据培训光环大数据培训HDFS namenode 在接受写操作时会记录日志,最早 HDFS 日志写本地,每次重启或出现故障后重启,通过本地镜像文件操作日志,就能还原到宕机之前的状态,不会出现数据不一致。如果要做高可用 (HA),日志写在单个机器上,这个机器磁盘出现问题,重启就恢复不了,导致数据不一致,出现的现象就是新建的文件不存在,删除成功的还在等诡异现象。这是分布式存储系统不能容忍的。在单机系统上是通过 WAL(write ahead log)日志来保证出问题后可恢复,在 HDFS 上对应的就是操作日志(EditLog) ,用于记录每次操作的行为描述。这里我们简单介绍下 editlog 的格式。文件格式编辑中的日志 edits_inprogress_txid,也就是后文提到的 segment,txid 代表该日志文件的第一个事务 IDFin
2、alized 日志即一致不再更改的日志文件 edits_fristTxit_endTxid内容格式文件头:有版本号 一个事务头标识文件内容1 操作类型 占 1 个字节2 日志长度 占 4 个字节光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/3 事务 txid 占 8 个字节4 具体内容5 checksum 4 个字节文件结尾:一位事务标识注意之前没有 journal 分布式日志时,每次 flush 日志时在该段日志后面加一个标识 INVALID_TXID,在下次 flush 时会覆盖该标识,但目前的版本去掉了这个标识通过 editlog 能做到单机版系统的可靠性,但是在分布式环境下,要保证 namenode 的高可用,至少需要两台 namemode。要做到高可用,高可靠,首先就是保证 HDFS 的操作日志 (EditLog) 有副本。但有了副本就引入了新的问题,多个副本之间的一致性怎么保证,这是分布式存储必须解决的问题。 为此 Clouder 公司开发了 QJM(Quorum Journal Manager)来解决这个问题。J
3、ournal Node 集群Journal node 是根据 paxos 思想来设计的,只有写到一半以上返回成功,就算本次写成功。所以 journal 需要部署 3 台组成一个集群,核心思想是过半 Quorum,异步写到多个 Journal Node。写日志过程editlog 写入到多个 node 的过程简单描述如下:ActiveNamenode 写日志到 Journal Node,采用 RPC 长连接光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/StandbyNamenode 同步已经 Finally 日志生成镜像文件,以及 Journal Node 直接同步数据,采用 HTTPActiveNamenode 每接收到事务请求时,都会先写日志,这个写日志的过程,网上有好多好的文章做分析,这里只是大概说下值得我们学习的地方以及一些好的设计思想。1 批量刷磁盘这个应该说是写日志的通用做法,如果每来一条日志都刷磁盘,效率很低,如果批量刷盘,就能合并很多小 IO(类似 MySQL 的 group commit)2 双缓冲区切换bufC
4、urrent 日志写入缓冲区bufReady 即将刷磁盘的缓冲区如果没有双缓冲区,我们写日志缓冲区满了,就要强制刷磁盘,我们知道刷磁盘不仅是写到操作系统内核缓冲区,还要刷到磁盘设备上,这是相当费时的操作,引入双缓冲区,在刷磁盘操作和写日志操作可以并发执行,大大提高了 Namenode 的吞吐量。恢复数据恢复数据是在 Active Namenode crash 后,standby namenode 接管后,需要变为 Active Namenode 后需要做的第一件事就是恢复前任 active namenode crash 时导致 editlog 在 journal node 的数据不一致。所以在 standby node 可以正式对外宣布可以工作时,需要让 journal node 集群的数据达到一致,下面主要分析恢复算法, 恢复算法官方说是根据 multi paxos 算法 。光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/Multi PaxosPaxos 协议是分布式系统里面最为复杂的一个协议,网上主要都是讲概念和理论,不较少
《QJM 核心源代码解读 Hadoop namenode 高可用性分析_光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《QJM 核心源代码解读 Hadoop namenode 高可用性分析_光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
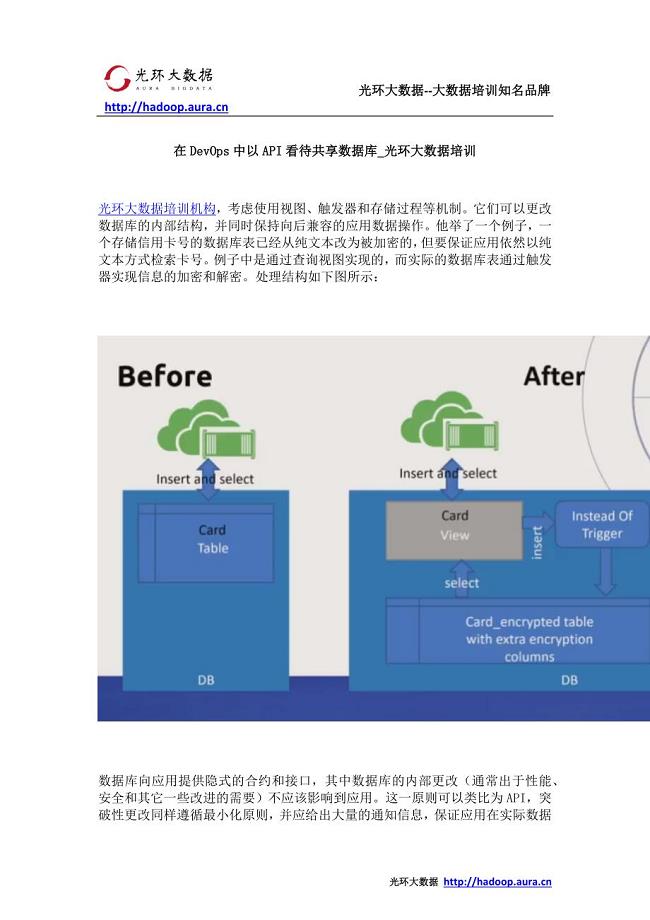
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
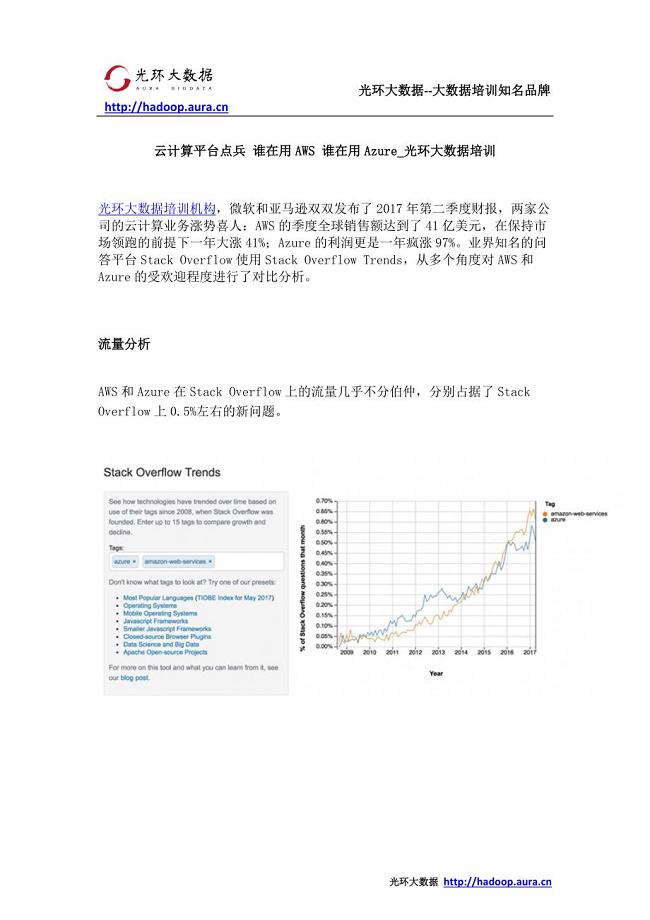
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 综合实践《巧手剪窗花》教学设计
综合实践《巧手剪窗花》教学设计
2022-11-05 10页
康定与《康定情歌》的不解之缘.doc
2023-12-02 7页
(最新整理)店长岗位职责说明书
2023-07-25 5页
2021年幼儿园小班第二学期教学工作计划
2023-02-08 11页
2020年在职级晋升集体谈话会上的讲话
2023-11-21 5页
2020部编版一年级语文上册单元知识点归类汇总
2023-06-01 10页
小学生经典团队游戏和室内游戏
2023-07-27 10页
电频车自动跟随系统.docx
2023-01-04 7页
确山县第四初级中学“礼仪制度传播主流价值”活动报告;
2022-11-03 3页
在新任科级干部任前集体廉政谈话会上的讲话
2024-02-05 4页