
PB级海量数据服务平台架构设计实践_光环大数据培训
18页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/PBPB 级海量数据服务平台架构设计实践级海量数据服务平台架构设计实践_ _光环大数据培训光环大数据培训光环大数据培训机构,基于 PB 级海量数据实现数据服务平台,需要从各个不同 的角度去权衡,主要包括实践背景、技术选型、架构设计,我们基于这三个方 面进行了架构实践,下面分别从这三个方面进行详细分析讨论:实践背景实践背景该数据服务平台架构设计之初,实践的背景可以从三个维度来进行说明:当前 现状、业务需求、架构需求,分别如下所示:当前现状当前现状收集了当前已有数据、分工、团队的一些基本情况,如下所示:数据收集和基础数据加工有专门的 Team 在做,我们是基于收集后并进 行过初步加工的基础数据,结合不同行业针对特定数据的需求进行二次 加工的。数据二次加工,会集成基础数据之外的其它有业务属性的数据,比如引 入第三方 POI 数据等。原始数据每天增量大约 3040TB 左右。计算集群采用 Spark on YARN 部署模式,大约 400 个节点。所有数据各种属性、行为信息,都是围绕大约
2、 40 亿的移动设备 ID 进行 很多倍膨胀,比如每天使用微信 App 的设备的行为信息。光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/参与该平台的研发人员,对实际数据业务需求了解不会非常深入,因为跨多个行业及其不同数据需求的变化较快。业务需求业务需求另外,实现的该数据服务平台,需要满足当前的基本数据业务需求,主要包括 使用平台的人员特点,需要支撑的各种基本数据需求,经过梳理,如下所示:平台初期面向内部业务人员使用,几乎没有技术背景。40 亿+的移动设备大表,包含各类设备 ID 及其设备属性,需要提供批量 匹配功能:给定一类或多类设备 ID 的批量文件,从大表中获取到匹配上 的设备信息(ID 及多个属性信息)。对 PB 级数据进行各种快速探索,输入各种过滤条件,如地域(国家/省/ 市/区)、地理围栏(地图圈选/上传文件/直接输入)、使用的 App 及分 类(安装/活跃)、时间范围(日/周/月)、POI 及分类等等,理论上不 限制条件个数,经验值最多在 56 个左右。输出主要包括明细信息、多维度统计(画像)、图表(热力图)等。平
3、台提供的数据服务,都是批量模式的计算,所以需要为用户提交的数据作业,给予准确的状态变化反馈。有小部分面向开发人员的需求:将在数据平台 Web 系统操作进行的数据 匹配、提取、探索等操作,进行服务化以供其他系统中的服务调用。架构需求架构需求在未来业务模式变化的情况下,能够非常容易地扩展,并尽量复用大部分核心 组件。同时,还要面向开发人员复用数据平台的数据业务服务,以增加平台利 用率,间接产出数据价值。考虑如下一些当前需要以及未来可能演变的架构需 求:光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/定义作业和任务的概念:作业是用户为满足一次业务需要而提交的数据获取请求,最终输出想要的数据结果;任务是为满足输出一个作业结果, 从逻辑上拆分成的基本计算单元。一个作业由多个任务的计算组合而完 成。对于一个作业输入的多个过滤条件,如果作为一个单独的计算任务,根本无法在 PB 量级的数据上输出结果,所以需要将作业拆分成多个任务 进行分别计算,最后输出结果。对用户作业状态的管理,具有一定的业务含义,基本不能在公司级别进 行复用,具体涉及内容包括
4、:排队、组成作业的任务列表管理、作业优 先级管理。任务是最基本的计算单位,设计能够协调整个任务计算的架构,可以分 离出任何业务状态,实现为无状态的任务计算架构,在公司级别可以复 用,比如大量基于 Spark 的计算可以抽象为任务计算。由于时间范围条件跨度需要支持几年(如 13 年),计算依赖的数据量 级在 TB 甚至 PB 级别,所以一定要通过预计算的方式压缩数据,并能提 供支持快速计算的方式。预计算可以使用 Spark 计算集群,每天通过控制计算所需资源进行大规 模 ETL 处理。ETL 处理,迫切需要一个简单、轻量的 ETL 作业调度系统,可以从开源 产品中甄选。采用原生 Spark 计算基本无法为平台上用户提供快速计算的体验,可能 会考虑列式分布式数据库,或基于 Bitmap 结构的分布式计算系统。面向开发人员,部分涉及业务相关内容的模块,第一阶段可以通过硬编 码方式处理业务逻辑,后续第二阶段可以基于对业务流程的熟悉来进行 改造,抽取通用业务逻辑规则,构建能够快速交付业务功能的模块。对平台架构进行分解,分离有状态和无状态模块,分离带业务属性和不 带业务属性的模块,保持模块轻量易于
《PB级海量数据服务平台架构设计实践_光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《PB级海量数据服务平台架构设计实践_光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
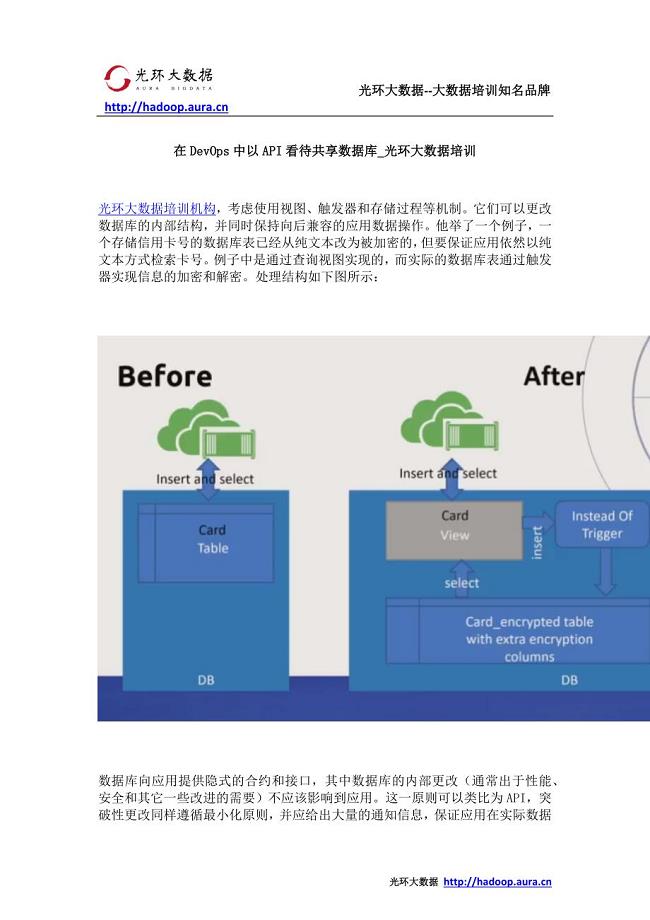
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
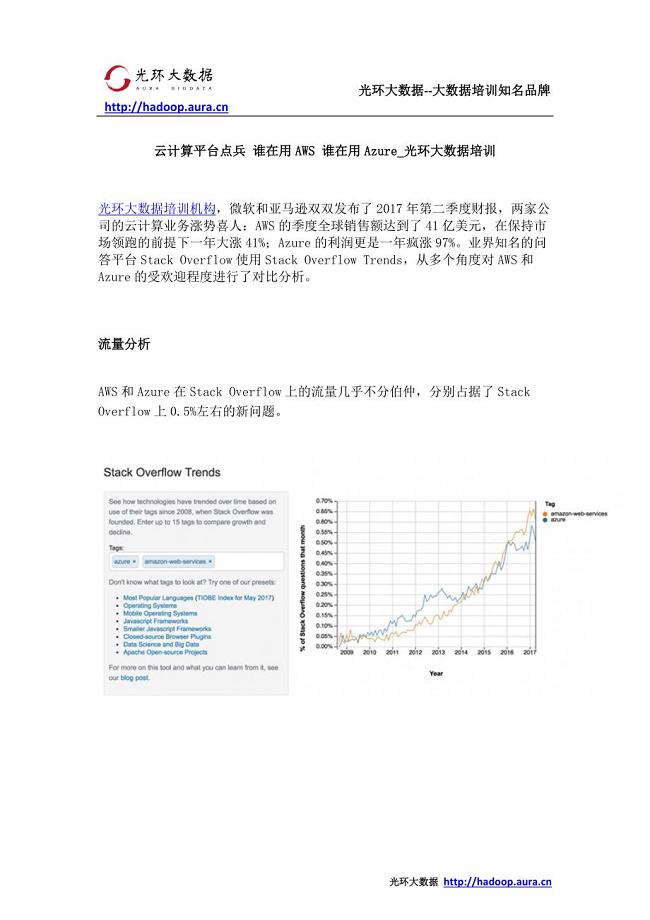
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 2020部编版一年级语文上册单元知识点归类汇总
2020部编版一年级语文上册单元知识点归类汇总
2023-06-01 10页
小学生经典团队游戏和室内游戏
2023-07-27 10页
电频车自动跟随系统.docx
2023-01-04 7页
确山县第四初级中学“礼仪制度传播主流价值”活动报告;
2022-11-03 3页
在新任科级干部任前集体廉政谈话会上的讲话
2024-02-05 4页
医院反恐防暴演练方案
2023-02-26 4页
餐厨垃圾及其处理方案(完整版)
2022-09-11 15页
全民义务植树工作总结
2022-10-19 6页
三年级语文上册病句修改专项专题训练
2023-05-16 6页
借款合同范本_9891
2022-10-21 6页