
park的误解-不仅spark是内存计算,hadoop也是内存计算_光环大数据培训
3页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/parkpark 的误解的误解- -不仅不仅 sparkspark 是内存计算,是内存计算,hadoophadoop 也是内存计算也是内存计算_ _光环大数据培训光环大数据培训市面上有一些初学者的误解,他们拿 spark 和 hadoop 比较时就会说,Spark 是内存计算,内存计算是 spark 的特性。请问在计算机领域,mysql,redis,ssh 框架等等他们不是内存计算吗?依据冯诺依曼体系结构,有什么技术的程序不是 在内存中运行,需要数据从硬盘中拉取,然后供 cpu 进行执行?所有说 sprk 的 特点是内存计算相当于什么都没有说。那么 spark 的真正特点是什么?抛开 spark 的执行模型的方式,它的特点无非就是多个任务之间数据通信不需要借 助硬盘而是通过内存,大大提高了程序的执行效率。而 hadoop 由于本身的模型 特点,多个任务之间数据通信是必须借助硬盘落地的。那么 spark 的特点就是 数据交互不会走硬盘。只能说多个任务的数据交互不走硬盘,但是 spr
2、k 的 shuffle 过程和 hadoop 一样仍然必须走硬盘的。误解一:Spark 是一种内存技术大家对 Spark 最大的误解就是 spark 一种内存技术。其实没有一个 Spark 开发者正式说明这个,这是对 Spark 计算过程的误解。Spark 是内存计算没有 错误,但是这并不是它的特性,只是很多专家在介绍 spark 的特性时,简化后 就成了 spark 是内存计算。什么样是内存技术?就是允许你将数据持久化在 RAM 中并有效处理的技术。 然而 Spark 并不具备将数据数据存储在 RAM 的选项,虽然我们都知道可以将数 据存储在 HDFS, HBase 等系统中,但是不管是将数据存储在磁盘还是内存,都 没有内置的持久化代码。它所能做的事就是缓存数据,而这个并不是数据持久 化。已经缓存的数据可以很容易地被删除,并且在后期需要时重新计算。但是有人还是会认为 Spark 就是一种基于内存的技术,因为 Spark 是在内 存中处理数据的。这当然是对的,因为我们无法使用其他方式来处理数据。操 作系统中的 API 都只能让你把数据从块设备加载到内存,然后计算完的结果再 存储到块设备
《park的误解-不仅spark是内存计算,hadoop也是内存计算_光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《park的误解-不仅spark是内存计算,hadoop也是内存计算_光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
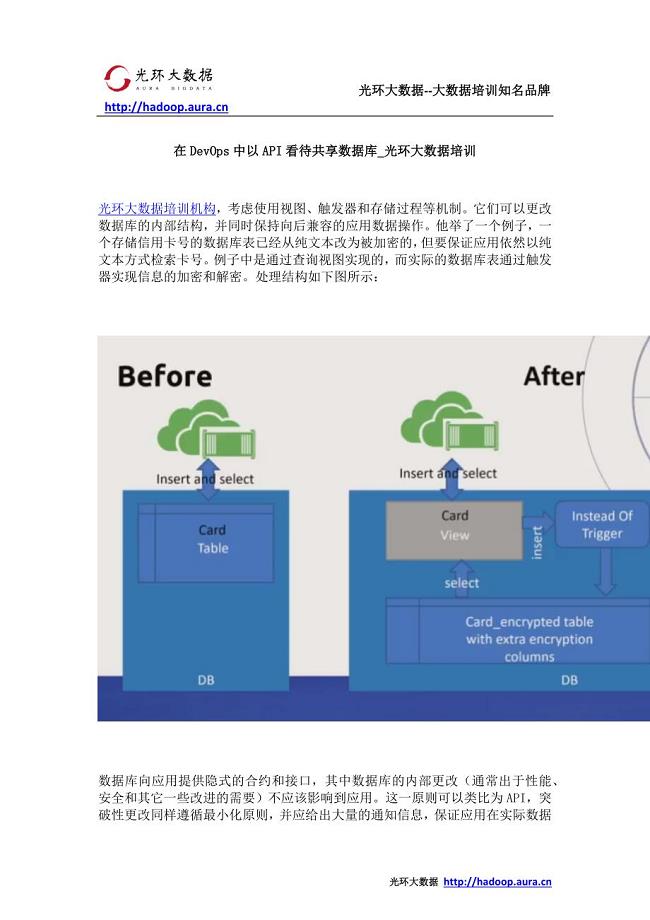
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
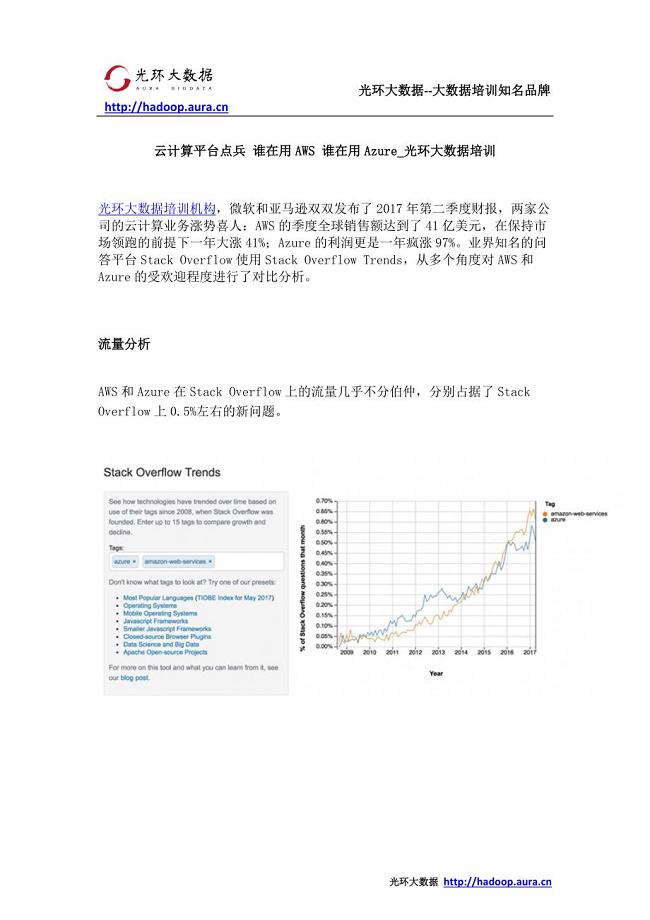
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 综合实践《巧手剪窗花》教学设计
综合实践《巧手剪窗花》教学设计
2022-11-05 10页
康定与《康定情歌》的不解之缘.doc
2023-12-02 7页
(最新整理)店长岗位职责说明书
2023-07-25 5页
2021年幼儿园小班第二学期教学工作计划
2023-02-08 11页
2020年在职级晋升集体谈话会上的讲话
2023-11-21 5页
2020部编版一年级语文上册单元知识点归类汇总
2023-06-01 10页
小学生经典团队游戏和室内游戏
2023-07-27 10页
电频车自动跟随系统.docx
2023-01-04 7页
确山县第四初级中学“礼仪制度传播主流价值”活动报告;
2022-11-03 3页
在新任科级干部任前集体廉政谈话会上的讲话
2024-02-05 4页