
0基础搭建Hadoop大数据处理经验分享_光环大数据培训
13页
1、 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/0 0 基础搭建基础搭建 HadoopHadoop 大数据处理经验分享大数据处理经验分享_ _光环大数据培训光环大数据培训大数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统 战略和技术的总称。虽然处理数据所需的计算能力或存储容量早已超过一台计 算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了 大规模扩展。在之前的文章中,我们曾经介绍过有关大数据系统的常规概念、处理过程, 以及各种专门术语,本文将介绍大数据系统一个最基本的组件:处理框架。处 理框架负责对系统中的数据进行计算,例如处理从非易失存储中读取的数据, 或处理刚刚摄入到系统中的数据。数据的计算则是指从大量单一数据点中提取 信息和见解的过程。下文将介绍这些框架:仅批处理框架:Apache hadoop仅流处理框架:Apache StormApache Samza混合框架:Apache SparkApache Flink大数据处理框架是什么?处理框架和处理引擎负责对数据系统中的数据进行计算。虽然
2、“引擎”和 “框架”之间的区别没有什么权威的定义,但大部分时候可以将前者定义为实 际负责处理数据操作的组件,后者则可定义为承担类似作用的一系列组件。例如 Apache Hadoop 可以看作一种以 MapReduce 作为默认处理引擎的处理 框架。引擎和框架通常可以相互替换或同时使用。例如另一个框架 Apache 光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:/Spark 可以纳入 Hadoop 并取代 MapReduce。组件之间的这种互操作性是大数据 系统灵活性如此之高的原因之一。虽然负责处理生命周期内这一阶段数据的系统通常都很复杂,但从广义层 面来看它们的目标是非常一致的:通过对数据执行操作提高理解能力,揭示出 数据蕴含的模式,并针对复杂互动获得见解。为了简化这些组件的讨论,我们会通过不同处理框架的设计意图,按照所 处理的数据状态对其进行分类。一些系统可以用批处理方式处理数据,一些系 统可以用流方式处理连续不断流入系统的数据。此外还有一些系统可以同时处 理这两类数据。在深入介绍不同实现的指标和结论之前,首先需要对不同处理类
3、型的概念 进行一个简单的介绍。批处理系统批处理在大数据世界有着悠久的历史。批处理主要操作大容量静态数据集, 并在计算过程完成后返回结果。批处理模式中使用的数据集通常符合下列特征.有界:批处理数据集代表数据的有限集合持久:数据通常始终存储在某种类型的持久存储位置中大量:批处理操作通常是处理极为海量数据集的唯一方法批处理非常适合需要访问全套记录才能完成的计算工作。例如在计算总数 和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录 的集合。这些操作要求在计算进行过程中数据维持自己的状态。需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从 持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程 中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持 久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较 高的场合。ApacheApache HadoopHadoop光环大数据光环大数据-大数据培训知名品牌大数据培训知名品牌http:/ 光环大数据光环大数据 http:
4、/Apache Hadoop 是一种专用于批处理的处理框架。Hadoop 是首个在开源社 区获得极大关注的大数据框架。基于谷歌有关海量数据处理所发表的多篇论文 与经验的 Hadoop 重新实现了相关算法和组件堆栈,让大规模批处理技术变得更 易用。新版 Hadoop 包含多个组件,即多个层,通过配合使用可处理批数据:HDFS:HDFS 是一种分布式文件系统层,可对集群节点间的存储和复制进行 协调。HDFS 确保了无法避免的节点故障发生后数据依然可用,可将其用作数据 来源,可用于存储中间态的处理结果,并可存储计算的最终结果。YARN:YARN 是 Yet Another Resource Negotiator(另一个资源管理器)的 缩写,可充当 Hadoop 堆栈的集群协调组件。该组件负责协调并管理底层资源和 调度作业的运行。通过充当集群资源的接口,YARN 使得用户能在 Hadoop 集群 中使用比以往的迭代方式运行更多类型的工作负载。MapReduce:MapReduce 是 Hadoop 的原生批处理引擎。批处理模式Hadoop 的处理功能来自 MapReduce 引擎。MapRed
《0基础搭建Hadoop大数据处理经验分享_光环大数据培训》由会员gua****an分享,可在线阅读,更多相关《0基础搭建Hadoop大数据处理经验分享_光环大数据培训》请在金锄头文库上搜索。

做运营60%靠思维,40%靠经验,你的思维跟得上吗_光环大数据培训

长沙BI大数据培训_BI大数据工程师需要具备哪些高薪技能_光环大数据培训

智慧交通大数据平台搭建过程及应用案例_光环大数据培训
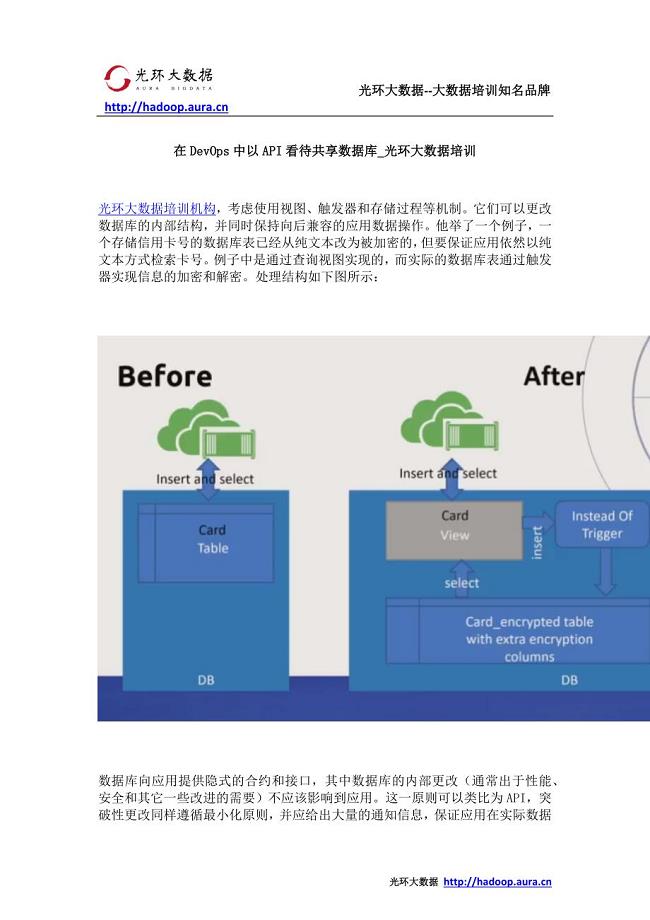
在DevOps中以API看待共享数据库_光环大数据培训

怎样才能成为一个高级Java工程师 —光环java培训机构

这可能是一篇数据化运营的大纲_光环大数据培训

自学大数据能找到工作吗_光环大数据培训

长沙大数据公司有哪些 参加大数据培训有钱途吗_光环大数据培训

中国大数据成熟盈利模型尚未建立_光环大数据培训

针对 MySQL 大规模数据库的性能和伸缩性的优化_光环大数据培训

怎样做数据分析_数据分析方法大全

怎么学习数据分析_数据分析软件汇总

怎样成为数据分析师_光环数据分析师培训

在大数据迅猛发展的今天隐私保护成了难题_光环大数据推出AI智客计划送2000助学金

长沙cpda数据分析培训_cpda考试流程
运营之道,千变万化,存乎一心_光环大数据培训

在Hadoop上运行Docker容器的六大陷阱_光环大数据培训
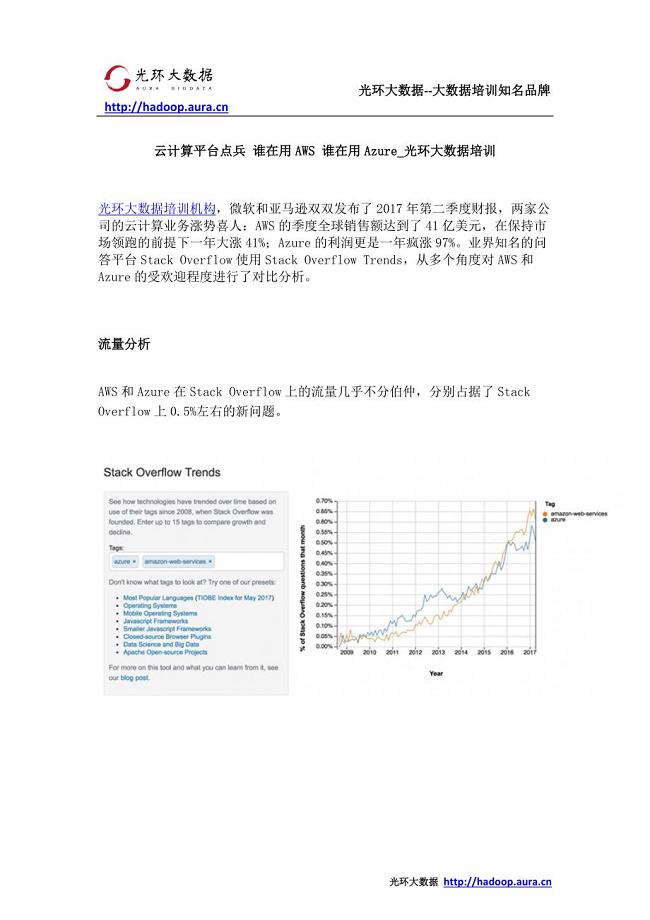
云计算平台点兵 谁在用AWS 谁在用Azure_光环大数据培训

自学java编程语言和参加java培训哪个更有前途—光环java培训机构

最用心的运营数据指标解读_光环大数据培训
 核桃乳产品平行生产管理制度
核桃乳产品平行生产管理制度
2023-07-25 4页
高一地理必修一复习提纲(人教版)
2023-06-16 11页
2020智慧园区行业分析调研报告
2023-09-24 42页
郭庚茂兰考讲话
2024-03-26 10页
农村致富带头人代表发言稿
2022-09-26 3页
预防食用野生菌中毒健康知识讲座.doc
2023-05-28 3页
Pcm量化13折线毕业论文.doc
2023-03-13 55页
全国重点建设职教师资培养培训基地“十一五”工作总结.doc
2023-06-13 11页
加入名师工作室一年来个人工作总结.docx
2023-05-25 4页
人教版高中物理选修3-1知识点归纳总结.doc
2024-02-28 7页