
论基于股票时间序列数据的关联规则挖掘研究
10页
1、编号:时间:2021年x月x日书山有路勤为径,学海无涯苦作舟页码:第1页 共1页南昌大学2003级硕士学位论文文献综述报告基于股票时间序列数据的关联规则挖掘研究Study on Mining Association Rules from Stock Time Series Data 系 别: 计算机科学与技术系专 业: 计算机应用技术研究方向: 人工智能研 究 生: 汪廷华导 师: 程从从(教授)2005年03月一引言随着计算机信息系统的日益普及,大容量存储技术的发展以及条形码等数据获取技术的广泛应用,人们在日常事务处理和科学研究中积累了大量的各种类型的数据。在这些数据中,有很大一部分是呈现时间序列(time series)类型的数据。所谓时间序列数据就是按时间先后顺序排列各个观测记录的数据集1,如金融证券市场中每天的股票价格变化;商业零售行业中,某项商品每天的销售额;气象预报研究中,某一地区的每天气温与气压的读数;以及在生物医学中,某一症状病人在每个时刻的心跳变化等等。然而,我们应该注意到:时间序列数据不仅仅是历史事件的记录,更重要的是蕴藏这些数据其中不显现的、有趣的模式。随着时间推
2、移和时间序列数据的大规模增长,如何对这些海量数据进行分析处理,挖掘其背后蕴藏的价值信息,对于我们揭示事物发展规律变化的内部规律,发现不同事物之间的相互关系,为人们正确认识事物和科学决策提供依据具有重要的实际意义。时间序列数据分析按照不同的任务有各种不同的方法,一般包括趋势分析、相似性搜索、与时间有关数据的序列模式挖掘、周期模式挖掘等2。本综述是针对证券业中股票时间序列分析的,试图通过列举、分析有关证券业中股票时间序列数据分析的原理、方法与技术,着重探讨数据挖掘中基于股票时间序列数据的关联规则挖掘的概念、原理技术、实施过程及存在的障碍和问题,以期能有新的发现和领悟。二股票时间序列传统研究方法概述随着我国市场经济建设的发展,人们的金融意识和投资意识日益增强。股票市场作为市场经济的重要组成部分,正越来越多地受到投资者的关注。目前股票投资已经是众多个人理财中的一种重要方式。不言而喻,如果投资者能正确预测股票价格、选准买卖时机,无疑会给投资者带来丰厚的收益。于是,在股票的预测和分析方面出现了大量的决策分析方法和工具,以期能有效地指导投资者的投资决策。目前,我国股市用得较多的方法概括起来有两类3:
3、一类是基本分析和技术分析,另一类是经济统计分析。1基本分析和技术分析在股票市场上,当投资者考虑是否投资于股票或购买什么股票时,一般可以运用基本分析的方法对股市和股票进行分析;而在买卖股票的时机把握上,一般可以运用技术分析的方法4。基本分析指的是通过对影响股票市场供求关系的基本因素(如宏观政治经济形势、金融政策、行业变动、公司运营财务状况等)进行分析,来确定股票的真正价值,判断未来股市走势,是长期投资者不可或缺的有效分析手段。技术分析是完全根据股市行情变化而加以分析的方法,它通过对历史资料(成交价和成交量)进行分析,来判断大盘和个股价格的未来变化趋势,探讨股市里投资行为的可能转折,从而给投资者买卖股票的信号,适合于投资者作短期投资。目前技术分析常用的工具是各种各样的走势图(K线图、分时图)和技术指标(MA、RSI、OBV等)。2经济统计学分析主要针对时间序列数据进行数学建模和分析。传统的时间序列数据分析已经是一个发展得相当成熟的学科,有着一整套分析理论和工具,是目前时间序列数据分析的主要方法,它主要用经济统计学的理论和方法对经济变量进行描述、分析和推算。传统时间序列数据分析的研究目的在于
4、5:分析特定的数据集合,建立数学模型,进行模式结构分析和实证研究;预测时间序列的未来发展情况。传统的时间序列数据分析最基本的理论是40年代分别由Norbor Wiener和Andrei Kolmogomor提出的。20世纪70年代,G.P.Box和G.M.Jenkins发表专著时间序列分析:预测和控制,对平稳时间序列数据提出了自回归滑动平均模型(ARMA),以及一整套的建模、估计、检验和控制方法,使得时序数据分析得以广泛运用于各种工程领域。其基本思想是根据各随机变量间的依存关系或自相关性,从而由时间序列的过去值及现在值来预测出未来的值。该模型以证券市场为非有效市场为前提,当期的股票价格变化不仅受当期随机因素的冲击,而且受前期影响。换句话说,就是历史信息会对当前的股票价格产生一定程度的影响。采用的方法一般是在连续的时间流中截取一个时间窗口(一个时间段),窗口内的数据作为一个数据单元,然后让这个时间窗口在时间流上滑动,以获得建立模型所需要的训练集6。7基于股票时间序列是一种混沌时间序列的认知,提出一种新颖的非线性时间序列预测模型,即滑动窗口二次自回归(MWDAR)模型,该模型使用部分的历史
《论基于股票时间序列数据的关联规则挖掘研究》由会员新**分享,可在线阅读,更多相关《论基于股票时间序列数据的关联规则挖掘研究》请在金锄头文库上搜索。

2023年高三模拟考试论述类题目.docx

机械加工设备安全系统操作规程

九三学社入社申请书2篇

羽毛饲料项目创业计划书写作模板

河南豫光金铅股份有限公司再生铅循环利用及高效清洁生产技改项目环境影响评价报告书.doc

7-、走进化学实验室笔记

2023年社会资本变迁视角下的农村合作机制创新路径分析.doc
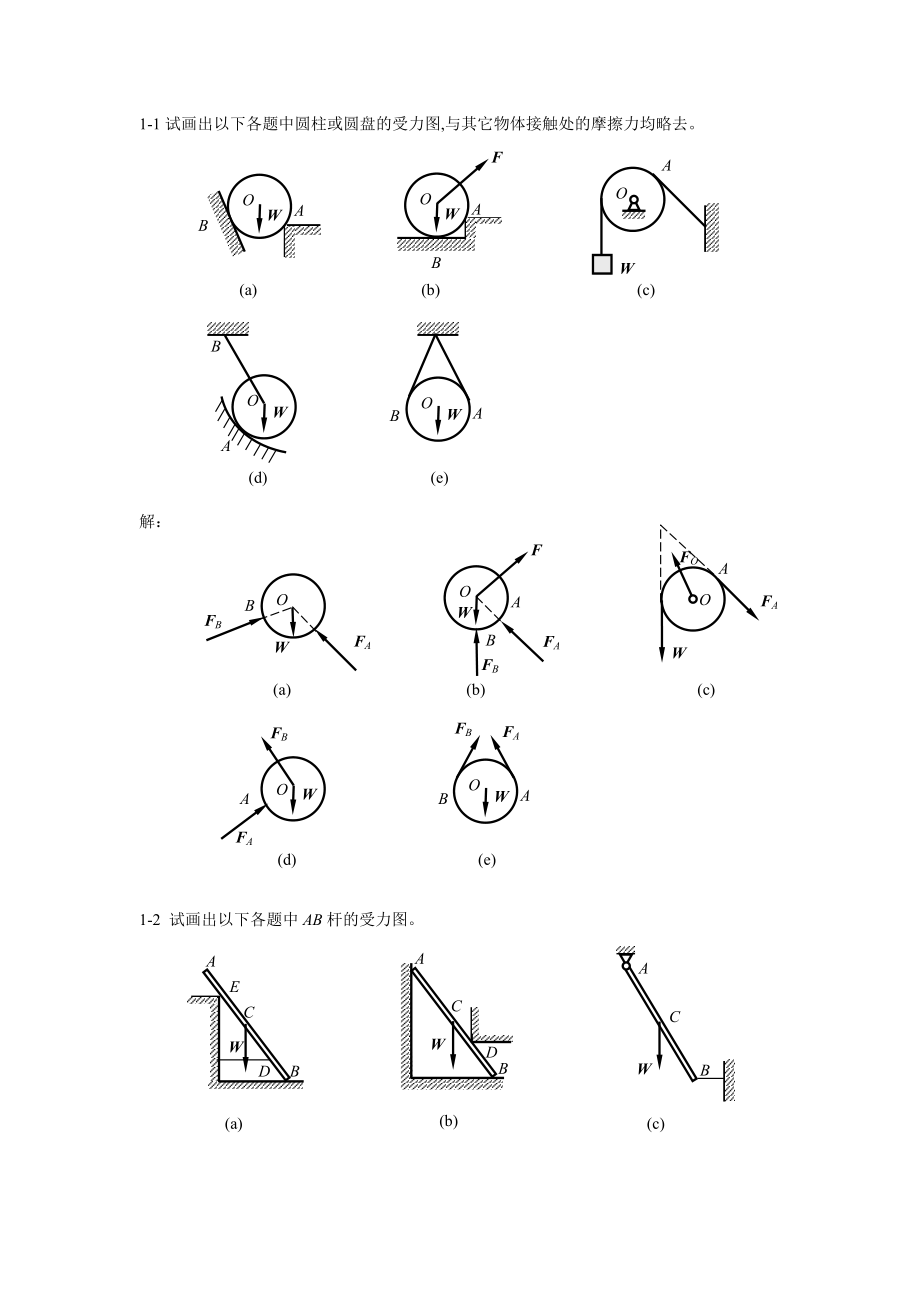
大学《工程力学》课后习题解答.doc

高炉烧穿事故应急抢险救灾预案

人教版五年级上学期语文总复习一单元模拟试卷.docx

小班科学优质课教案及教学反思《有趣的传声筒》.docx

第一学期苏教版七年级语文期中试卷及答案

【分层练习】《候银匠》(语文语文版九上).docx

职业道德与法律期末试卷(中职)含答案.doc

建设大数据与数字工厂项目商业计划书写作模板

传统特色食品产业园标准化厂房及配套基础设施项目建议书写作模板立项审批

2020年骨干教师跟岗学员跟岗总结范文

红米手机内置SD卡与外置SD卡互换.doc

渔业养殖创业计划书

2022年保护眼睛演讲稿15篇
 有文采的班主任工作总结范本(二篇).doc
有文采的班主任工作总结范本(二篇).doc
2022-08-07 9页
2023年人力资源个人总结标准范文(二篇).doc
2023-07-24 10页
银行职工在岗总结(2篇).doc
2024-01-30 3页
人教版六年级语文下册《汤姆索亚历险记》教学反思
2024-02-03 2页
红楼梦的读书心得集锦15篇
2022-09-09 22页
外贸业务员个人年底工作总结(二篇).doc
2023-09-19 7页
财务人员年度个人工作总结格式版(二篇).doc
2022-12-28 5页
热门建筑合同集合6篇
2022-08-15 21页
背影初中作文
2023-12-15 27页
财务经理2023年终工作总结范文(2篇).doc
2022-12-01 5页