
软件测试中机器学习的运用探讨
8页
1、软件测试中机器学习的运用探讨1.2.1 关于软件安全可靠性的研究在软件安全可靠性研究的 30 篇文献中, 多数是针对移动应用软件的安全性和可靠性的 检测和预测,少数文献是针对Window和Linux应用软件3,14,19。对于Window和Linux应用软件的安全性和可靠性检测和预测,通常是对API分类和API 调用序列进行分析、利用工具从源码中提取信息、监控并记录软件行为等方法提取信息作为 模型的输入特征, 利用支持向量机、逻辑回归、随机森林等常用的机器学习模型在虚拟机或 沙箱中进行实验和分析。对于Android应用程序6,8,12,主要是利用AAPT提取APK的元信息,同时结合应用 程序的性能数据、网络流量、软件行为等信息对应用程序进行静态和动态分析, 提取特征集, 利用常用的机器学习算法进行模型构建、训练、预测和评估, 实验结果表明在检测新软件是 否是恶意软件, 利用机器学习方法对软件安全性和可靠性的检测和预测相对于传统的杀毒软 件更快速且更高效。1.2.2、关于软件缺陷的研究软件缺陷是计算机软件或程序中存在的某种破坏正常运行能力的问题、错误, 或者隐藏 的功能缺陷。在软件缺陷方
2、面, 所阅读的部分研究文献针对缺陷预测、缺陷定位和缺陷分类 进行了研究。(1) 软件缺陷预测软件缺陷预测是用已有的历史数据来预测软件中是否存在缺陷。研究文献中主要以静态 分析为主, 动态分析为辅, 利用机器学习算法进行模型构建、训练和评估, 其中静态分析中 提取的特征主要包括:面向对象准则、继承准则、代码准则等特征。由于静态分析所得到的特 征较多, 且不同的特征对预测缺陷的权重不同, 且分类类别不平衡, 因此, 在将这些特征进 行机器学习训练时, 需要对数据进行清洗后才能用于学习和训练, 以避免产生较大的误差。 随着软件测试领域逐渐发展, 软件缺陷数据的积累越来越多, 充分利用已积累的缺陷数据, 可以减少开发人员和测试人员的工作量, 提高软件测试的效率。(2) 软件缺陷定位软件缺陷定位在软件测试领域是一个较为困难的问题。目前, 大多数的缺陷需要人为查 找和排除, 代码走查和审查成为了查找和排除缺陷的重要手段和方法, 但是此方法会耗费大 量的人力和时间, 因此, 如何快速有效地定位软件缺陷成为了亟待解决的问题。在研究文献 中,软件缺陷定位的方法分为两类,一类是Li等1 基于模糊理论进行定
3、位,即把历史数据 中产生的软件缺陷进行抽象和概括;另一类类似于软件缺陷预测的方法, Jonsson 等17和 Le等19以静态分析进行模型构建、训练和评估。(3) 软件缺陷分类软件缺陷分类主要是判别提交的缺陷是否是真正的缺陷。在研究文献中, 不同的学者对 缺陷的提取特征不同。例如:在开源的项目中,Pandey等提取JIRA和BUGZILLA中的缺陷描 述、发现缺陷的步骤、缺陷隶属的项目等信息作为特征;在众包测试中, Wang 等提取交叉领 域的历史测试数据作为特征;在软件开发项目中, 提出软件的静态分析准则作为特征。在缺 陷管理平台的众多缺陷中, 准确地判断缺陷可以较少开发人员和测试人员的工作量。但是, 随着众包测试和开源工具的增多, 检测缺陷的重复提交还需更进一步研究。(4) 缺陷复现在缺陷管理平台中, 不同的缺陷复现的难易程度是不一样的, 如闪退或崩溃类型的缺 陷。Gu等通过对软件历史版本的缺陷复现的路径分析来预测新缺陷复现的难易程度在缺陷 修复的过程中, 给开发人员提供帮助。1.2.3、基于源码的研究基于源码的研究主要是对源码进行静态分析找出源码中的缺陷。此研究主题最重要的是 对
4、源码进行抽象语法数、函数调用图、符号执行等方法的静态代码分析, 提取有效的特征进 行模型构建、训练和评估。基于源码的研究大致可分为代码重用、代码相似度的检测、代码 审查、缓冲区溢出检测。代码重用和代码相似度检测类似, 即检测源码中的相似的代码, 对 相似的代码进行封装, 减少开发的工作量和代码维护成本。在有源码的基础下, 对源码进行 分析可为软件质量提供更好的保障。1.2.4、其他(1) 测试用例优化回归测试在整个软件测试过程中占有较大的比重, 软件开发的各个阶段都会进行多次回 归测试。在回归测试过程中, 测试用例优化是用来解决如何在巨大的测试用例库中选择较少 的测试用例以达到较大的代码覆盖率和功能覆盖率的问题。在研究文献中, 不同的研究者对 测试用例优化问题进行了研究, 以整个测试用例库作为特征集, 通过对用例自然语言处理、 执行用例后的代码覆盖率、变异得分等对测试用例库进行降维, 去除冗余的测试用例, 再将 得到的数据进行模型构建、训练和评估。(2) 自动化测试自动化测试在软件测试过程中有极其重要的作用, 自动化测试能减少测试人员的工作量, 提高测试效率。Rosenfeld等利用机
《软件测试中机器学习的运用探讨》由会员cl****1分享,可在线阅读,更多相关《软件测试中机器学习的运用探讨》请在金锄头文库上搜索。

会计实务操作.docx

池州关于成立集成电路研发公司可行性报告

农村公厕管理制度范本(六篇)

.“护理安全小贴示”在预防住院患者跌倒中的应用
![《闻王昌龄左迁龙标遥有此寄》教学设计[133].docx](https://union.152files.goldhoe.com/2023-9/25/42fe63f8-df02-4984-a993-961bad0101a4/pic1.jpg)
《闻王昌龄左迁龙标遥有此寄》教学设计[133].docx

电缆故障测试仪DWA10使用说明书汇总.doc

甲基萘项目建议书写作模板

公关及品牌推广项目建议书-商业计划书

全国通用版2022年高考语文一轮复习专题十一辨析并修改蹭真题体验亮剑高考

精彩呼吸科护士述职报告范文5篇.doc
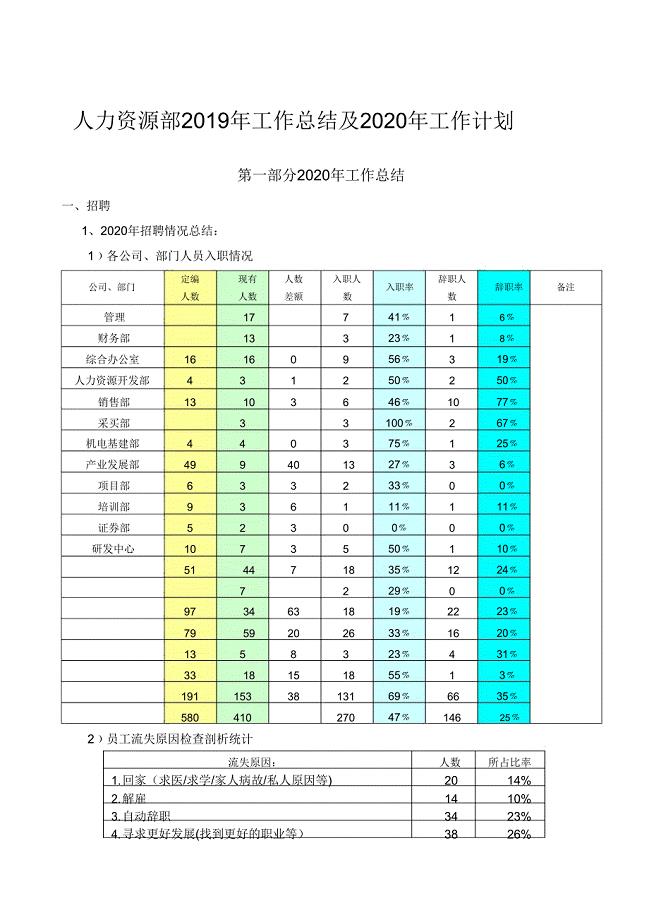
2019工作总结及工作计划.doc

2023年学校升旗仪式领导讲话稿100字6篇

2023年城管个人年终小结

第四编商标权法律制度

药品批发公司药品安全应急专项预案.doc

北海路小学健康教育教案表格六一班.doc

民间消暑降温方法.doc

小学部工作总结计划计划.docx

学生会组织部总结范文.doc

幼儿园小班小班上学期工作计划(9篇).doc
 电拖课程设计小型单片变压器设计
电拖课程设计小型单片变压器设计
2023-05-24 19页
人力资源管理信息系统课程设计.doc
2022-10-18 34页
银行后台员工年终总结.doc
2022-11-06 23页
长沙水泵厂DM155
2023-03-08 3页
临床重点专科建设管理办法
2022-09-04 9页
反渗透浓水浓缩处理技术方案
2023-11-01 31页
《西游记》名著语段阅读专项练习题 (附答案)
2023-05-02 5页
机械挂靠协议.doc
2023-11-20 4页
高效浅层气浮系统技术说明
2023-05-07 14页
爆破钻孔施工合同
2023-03-25 4页