
数据分析面试题1
36页
1、 DC 共享平台数据分析岗笔试面试题 本材料是由 DataCastle 从谷歌、微软、facebook、百度等企业的网络公开招 聘题中进行精选,并附上详细解析,适合应聘数据分析岗位的求职者,未经同意不 得转载,请联系 提前沟通,未经授权的转载 会联系法务进行处理。 1.一般,K-NN 最近邻方法在( )的情况下效果较好 A.样本较多但典型性不好 B.样本较少但典型性好 C.样本呈团状分布 D.样本呈链状分布 答案:B 解析: 样本呈团状颇有迷惑性,这里应该指的是整个样本都是呈团状分布,这样 kNN 就发挥不出其求近邻的优势了, 整体样本应该具有典型性好, 样本较少, 比较适宜。 2.一个包里有 5 个黑球,10 个红球和 17 个白球。每次可以从中取两个球出来,放 置在外面。那么至少取_次以后,一定出现过取出一对颜色一样的球。 A.16 B.9 C.4 D.1 答案:A 解析: 考虑最坏的情况,前 10 次取出的都是红球+白球的组合,后 5 次取出的都是黑 球+白球的组合,最后只剩下两个白球,则再取 1 次必取出相同颜色的球,因此总计 16 次。 3.用直接插入排序方法对下面 4 个
2、序列进行排序(由小到大),元素比较次数最少的是 ( ) A.94,32,40,90,80,46,21,69 B.32,40,21,46,69,94,90,80 C.21,32,46,40,80,69,90,94 D.90,69,80,46,21,32,94,40 答案:C 解析: 插入排序的原理是将第i个数插入到已经排列好的数据中, 因此原序列越有序, 比较次数越少 4.下面有关分类算法的准确率,召回率,F1 值的描述,错误的是? A.准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查 准率 B.召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是 检索系统的查全率 C.正确率、召回率和 F 值取值都在 0 和 1 之间,数值越接近 0,查准率或查全率就 越高 D.为了解决准确率和召回率冲突问题,引入了 F1 分数 答案:C 解析: 对于二类分类问题常用的评价指标是精准度(precision)与召回率(recall) 。 通常以关注的类为正类,其他类为负类,分类器在测试数据集上的预测或正确或不 正确,4 种情况出现的总数分别记作: TP将正类预测为
3、正类数 FN将正类预测为负类数 FP将负类预测为正类数 TN将负类预测为负类数 由此: 精准率定义为:P = TP / (TP + FP) 召回率定义为:R = TP / (TP + FN) F1 值定义为: F1 = 2 P R / (P + R) 精准率和召回率和 F1 取值都在 0 和 1 之间,精准率和召回率高,F1 值也会高,不 存在数值越接近 0 越高的说法,应该是数值越接近 1 越高。 5.Naive Bayes 是一种特殊的 Bayes 分类器,特征变量是 X,类别标签是 C,它的一个 假定是:() A.各类别的先验概率 P(C)是相等的 B.以 0 为均值, 2 2 为标准差的正态分布 C.特征变量之间是相互独立的 D.P(X|C)是高斯分布 答案:C 解析: 朴素贝叶斯的条件就在于假设每个变量相互独立 6.下列不是 SVM 核函数的是: A.多项式核函数 B.logistic 核函数 C.径向基核函数 D.Sigmoid 核函数 答案:B 解析: SVM 核函数包括线性核函数、多项式核函数、径向基核函数、高斯核函数、幂 指数核函数、拉普拉斯核函数、ANOVA 核函数
4、、二次有理核函数、多元二次核函 数、逆多元二次核函数以及 Sigmoid 核函数 7.(多选)数据清理中,处理缺失值的方法是? A.估算 B.整例删除 C.变量删除 D.成对删除 答案:A,B,C,D 解析: 数据清理中,处理缺失值的方法有两种: 删除法: 1)删除观察样本 2)删除变量:当某个变量缺失值较多且对研究目标影响不大时,可以将整 个变量整体删除 3)使用完整原始数据分析:当数据存在较多缺失而其原始数据完整时,可 以使用原始数据替代现有数据进行分析 4)改变权重:当删除缺失数据会改变数据结构时,通过对完整数据按照不 同的权重进行加权,可以降低删除缺失数据带来的偏差 查补法:均值插补、回归插补、抽样填补等 成对删除与改变权重为一类 估算与查补法为一类 8.在 Logistic Regression 中,如果同时加入 L1 和 L2 范数,会产生什么效果() A.可以做特征选择,并在一定程度上防止过拟合 B.能解决维度灾难问题 C.能加快计算速度 D.可以获得更准确的结果 答案:A 解析: L范数具有系数解的特性,但是要注意的是,L没有选到的特征不代表不重 要,原因是两个高相关性
《数据分析面试题1》由会员suns****4568分享,可在线阅读,更多相关《数据分析面试题1》请在金锄头文库上搜索。

土地管理与地籍测量---第八章界址点测量
人机工程学案例分析(2)

工程安全培训_201303

第9章房地产投资决策分析

第2章房地产经纪制度

ACM程序设计-东北林业大学acm05

《亲爱的汉修先生》读书交流会

中原_深圳新世界尖岗山项目市场汇报_40P_2012年_别墅_项目分析_量价走势

五年级数学质量分析演示文稿

人工智能小镇-智慧小镇建设20180525

景观基本知识及发展历程

建设工程信息管理(2)

机电驱动技术第二章步进驱动技术
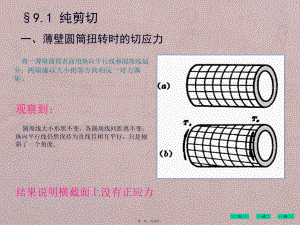
工程力学-第9章圆轴扭转时的应力变形分析与强度刚度设计

第一章第二节幼儿园文化环境建设的原则

第一章检测技术的基础知识

第一章__现代表面工程技术

第六章钢结构工程

第9节项目试运行管理

班主任工作经验交流课件(4)
 社会单位消防安全标准化管理建设标准
社会单位消防安全标准化管理建设标准
2023-11-17 13页
7王崧舟先生《桃花心木》教学实录
2023-04-30 14页
南开大学21春《信托与租赁》离线作业一辅导答案72
2023-12-28 10页
中国医科大学2022年3月《五官科护理学》期末考核试题库及答案参考54
2022-12-07 14页
大连理工大学22春《单片机原理及应用》综合作业二答案参考35
2023-11-29 13页
北京中医药大学22春《方剂学Z》综合作业二答案参考58
2023-11-26 15页
南开大学21春《初级博弈论》在线作业二满分答案77
2023-02-09 17页
2017六年级下册数学A卷月考一
2023-07-24 5页
世说新语练习题
2023-03-10 11页
重庆大学22春《高电压技术》综合作业二答案参考65
2023-02-01 13页