
判别分析建模
37页
1、统计与应用数学学院,STATISTICS & APPLIED MATHEMATICS,判别分析建模方法,李柏年,目 录,一,二,三,四,五,马氏距离判别分析,BAYES判别分析,贴近度判别分析,DNA序列的处理方法,判别分析的误差估计,六,建模实例分析,一,马氏距离判别分析,1.马氏距离:马氏距离是由印度统计学家马哈拉诺比斯(PC Mahalanobis)提出的,由于马氏距离具有统计意义,在距离判别分析时经常应用马氏距离.,(1) 同一总体的两个向量之间的马氏距离,其中 为总体协方差矩阵.,(2) 一个向量到一个总体的马氏距离,MATLAB中有一个命令: Mahal-计算马氏平方距离 请同学们利用 help 学习这个命令,G=1,2,4;4,5,6; mahal(G,G),(3) 两个总体之间的马氏距离,设有两个总体G1,G2,两个总体的均值向量分别为 1, 2协方差矩阵相等,皆为,则两个总体之间的马氏距离为,通常,在判别分析时不采用欧氏距离的原因在于,该距离与量纲有关.,2. 两个总体的马氏距离判别,(1). 两个总体协方差矩阵相等,由于实际问题中只能得到两个样本的协方差矩阵S1,S
2、2,因此当两个总体协方差矩阵相等时如何确定总体的协方差矩阵S ?,其中n1,n2分别为两个样本的容量.,判别步骤:, 计算A、B两类的均值向量与协方差阵;,ma=mean(A),mb=mean(B),S1=cov(A),S2=cov(B), 计算总体的协方差矩阵,其中n1,n2分别为两个样本的容量., 计算未知样本x到A,B两类马氏平方距离之差 d=(x-ma)S-1(x-ma)- (x-mb)S-1(x-mb), 若d0,则x属于B类,例1.现测得6只Apf和9只Af蠓虫的触长,翅长数据 Apf:(1.14,1.78), (1.18,1.96), (1.20,1.86), (1.26,2.00), (1.28,2.00), (1.30,1.96) Af:(1.24,1.72), (1.36,1.74), (1.38,1.64), (1.38,1.82), (1.38,1.90), (1.40,1.70), (1.48,1.82),(1.54,1.82), (1.56,2.08),若两类蠓虫协方差矩阵相等,试判别以下的三个蠓虫属于哪一类?,(1.24,1.8),(1.28,1.84),
3、(1.4,2.04),图1 Apf与Af蠓虫分布的散点图,解:,apf=1.14,1.78; 1.18,1.96;1.20,1.86;1.26,2.;1.28,2;1.30,1.96;,af=1.24,1.72;1.36,1.74;1.38,1.64;1.38,1.82;1.38,1.90; 1.40,1.70;1.48,1.82;1.54,1.82;1.56,2.08;,x= 1.24,1.8;1.28,1.84; 1.4,2.04;,故三个蠓虫均属Apf.,m1=mean(apf);m2=mean(af);s1=cov(apf);s2=cov(af);,S=(5*s1+8*s2)/13;,D =-4.3279 -2.7137 -3.9604,输入:Y是要判别的 样本点,通常是矩阵 X是已知总体的样本,通常是矩阵 输出:d是Y的每个行向量到总体X的马氏距离 的平方,是一个列向量(m行),两个总体的协方差矩阵不等时,有如下判别方法,(2) 两个总体协方差矩阵不相等,例2.对例1若两总体协方差矩阵不等,试判别,解:,apf=1.14,1.78; 1.18,1.96;1.20,1.86;1
4、.26,2.;1.28,2;1.30,1.96;,af=1.24,1.72;1.36,1.74;1.38,1.64;1.38,1.82;1.38,1.90; 1.40,1.70;1.48,1.82;1.54,1.82;1.56,2.08;,x= 1.24,1.8;1.28,1.84; 1.4,2.04;,d=mahal(x,Apf)-mahal(x,Af),若d0,则x属于Af;若d0,则x属于Apf.,Ans: d =1.7611 3.8812 3.6468,故三个蠓虫均属Af.,从例1和例2,发现两个总体的协方差矩阵是否相等,得到的结论可能不同,因此在解决实际问题时,首先要判别两个总体的协方差矩阵是否相等?,对于例1,应用检验程序如下:,n1=6;n2=9;p=2;s=(5*s1+8*s2)/13; Q01=(n1-1)*(log(det(s)-log(det(s1)-p+trace(inv(s)*s1), Q02=(n2-1)*(log(det(s)-log(det(s2)-p+trace(inv(s)*s2),ans: Q01 = 2.5784, Q02 = 0.7418,对
《判别分析建模》由会员suns****4568分享,可在线阅读,更多相关《判别分析建模》请在金锄头文库上搜索。

土地管理与地籍测量---第八章界址点测量
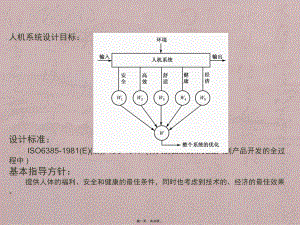
人机工程学案例分析(2)

工程安全培训_201303

第9章房地产投资决策分析

第2章房地产经纪制度

ACM程序设计-东北林业大学acm05

《亲爱的汉修先生》读书交流会

中原_深圳新世界尖岗山项目市场汇报_40P_2012年_别墅_项目分析_量价走势

五年级数学质量分析演示文稿

人工智能小镇-智慧小镇建设20180525

景观基本知识及发展历程

建设工程信息管理(2)

机电驱动技术第二章步进驱动技术
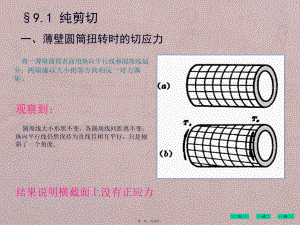
工程力学-第9章圆轴扭转时的应力变形分析与强度刚度设计

第一章第二节幼儿园文化环境建设的原则

第一章检测技术的基础知识

第一章__现代表面工程技术

第六章钢结构工程

第9节项目试运行管理

班主任工作经验交流课件(4)
 优质护理培训课件
优质护理培训课件
2023-12-11 28页
怎么练好护理操作课件
2023-12-11 28页
面瘫的治疗与护理课件
2023-12-11 27页
脑卒中患者护理课件模板
2023-12-11 31页
护理反向交班课件
2023-12-11 27页
护理案例比赛课件题目
2023-12-11 27页
医院icu护理课件
2023-12-11 33页
乙肝的护理课件
2023-12-11 28页
中药坐浴护理课件
2023-12-11 26页
口腔护理课件题目
2023-12-11 29页