
feng笔记-spss操作中的各种检验统计量和判别准则(完整手册10天完成)
22页
1、SPSS操作中的各种检验统计量和判别准则 (冯登超整理 2011 3.163.25)专题一 回归分析1 一元线性回归分析 (Analyze-Regression, Linear)(1) 拟合优度检验: 检验样本数据聚集在样本回归直线周围的密集程度,从而判断回归方程对样本数据的代表程度。拟合优度用判定系数R2实现。越接近1,说明回归直线的拟合程度越好。越接近0,说明回归直线的拟合程度越差。(2) 回归方程的显著性检验(F检验)回归方程的显著性检验是对因变量和所有自变量之间的线性关系是否显著的一种假设检验。如果零假设成立,说明回归总体是无显著线性的,即所有自变量对y没有显著的线性作用;反之说明回归总体存在线性关系。若F值大于临界值,则拒绝原假设(回归总体无显著线性关系),接受被选假设。若F值小于临界值,接受原假设,回归总体有显著线性关系。即 在ANOVA表中,若Sig0.05, 有显著差异,(Ho假设为x,y之间无显著线性关系),说明自变量x和因变量y之间确实有线性回归关系。回归方程的显著性检验只能检验所有回归系数是否与零有显著性差异,若无显著性差异,则接受零假设,回归总体不存在线性关系。
2、(3) 回归系数的显著性检验(t检验)回归系数显著性检验一般采用t检验方法。如果双侧t检验中,t的绝对值大于临界值(或者(pa),则接受原假设,说明x对y 没有显著影响。在一元线性回归分析中,回归方程的显著性检验可以代替回归系数的显著性检验,并且F=t2。但是,在一般的多元回归条件下两种检验要说明的问题不同,作用不同,不能相互替代。 在Coefficients表中,t为回归系数检验统计量,Sig为相伴概率值p。若p0.05,说明回归系数和0有显著差别,说明该回归方程有意义。在Use probalitity of F: 当一个自变量的F统计量的相伴概率值Sig=0.10时,不能拒绝Ho,认为该变量对因变量的影响是不显著的,应从回归方程中剔除。在Use F value中,表示以回归系数显著性检验中的各自变量的F统计量作为自变量进入模型或从模型剔除的准则。在变量的选择/剔除中,Entry(默认值3.84),表示当一个变量的F值3.84时,该变量被选入模型;Removal(默认值2.71),表示当一个变量的F值2.71时,该变量从模型中被剔除。2. 多元线性回归分析 研究两个或两个以上自变量对
3、一个因变量的数量变化关系。(1) 拟合优度检验,越接近1,说明回归平面的拟合程度越好。越接近0,说明回归平面的拟合程度越差。修正的考虑的是平均的残差平方和,在线性回归分析中,越大越好。(2)回归方程的显著性检验(F检验) 若F值较大,说明自变量造成的因变量的变动远远大于随机因素对因变量造成的影响。此外,F统计量也能反映回归方程的拟合优度。若回归方程的拟合优度高,F统计量越显著;F统计量越显著;回归方程的拟合优度越高。F检验中,H0假设是,设各个系数0,即各个自变量与因变量无线性关系。若 ,则拒绝原假设 H0,认为所有回归系数同时与零有显著差异,自变量与因变量之间存在显著的线性关系,自变量的变化确实能反映因变量的线性变化,回归方程显著。 若,接受原假设H0,认为所有回归系数同时与零无显著差异,自变量和因变量之间不存在显著的线性关系,自变量的变化无法反映因变量的线性变化,回归方程不显著。(3) 回归系数的显著性检验(t检验)回归系数的显著性检验是检验各个自变量对因变量y的影响是否显著,从而找出哪些自变量对y的影响是重要的,哪些是不重要的。H0假设为:。若零假设成立,说明对y没有显著影响,即
4、 自变量与因变量的线性关系不明显,反之,说明对因变量y具有显著的影响。采用t检验。若或者pa,接受原假设H0,认为该回归系数与零无显著差异,该自变量与因变量之间不存在显著的线性关系,它的变化无法反映因变量的线性变化,应该剔除出回归方程中。Analyze-Regression-Linear Regression, 在Correlations 表中,可以分析各个变量之间的相关系数。相关系数越大,说明各变量越相关。Model Summary 表中, 分析R,R square, 利用该值看样本回归效果。该值越大,说明样本数据和回归方程的拟合度越高。即分析样本的回归效果。Anova表,(方差分析表),利用统计量F和相伴概率Sig,同时分析多个自变量和因变量之间是否存在线性回归关系。Coefficients回归系数表,利用t分布的Sig值分析全部自变量和因变量之间是否存在显著线性关系。Residuals Statistics表,分析各个残差结果。3. 非线性回归分析研究在非线性相关条件下,自变量对因变量的数量变化关系。其中,多项式模型在非线性回归分析中占据重要地位。当因变量和自变量之间的关系未知时
《feng笔记-spss操作中的各种检验统计量和判别准则(完整手册10天完成)》由会员suns****4568分享,可在线阅读,更多相关《feng笔记-spss操作中的各种检验统计量和判别准则(完整手册10天完成)》请在金锄头文库上搜索。

土地管理与地籍测量---第八章界址点测量
人机工程学案例分析(2)

工程安全培训_201303

第9章房地产投资决策分析

第2章房地产经纪制度

ACM程序设计-东北林业大学acm05

《亲爱的汉修先生》读书交流会

中原_深圳新世界尖岗山项目市场汇报_40P_2012年_别墅_项目分析_量价走势

五年级数学质量分析演示文稿

人工智能小镇-智慧小镇建设20180525

景观基本知识及发展历程

建设工程信息管理(2)

机电驱动技术第二章步进驱动技术
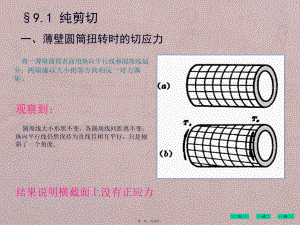
工程力学-第9章圆轴扭转时的应力变形分析与强度刚度设计

第一章第二节幼儿园文化环境建设的原则

第一章检测技术的基础知识

第一章__现代表面工程技术

第六章钢结构工程

第9节项目试运行管理

班主任工作经验交流课件(4)
 中考名著《朝花夕拾》阅读自我检测100题
中考名著《朝花夕拾》阅读自我检测100题
2024-03-05 67页
中考名著《海底两万里》阅读自我检测100题
2024-03-05 58页
绿色希望共筑生命之林——记植树节活动感悟
2024-02-27 2页
珍爱生命之源共筑绿色水世界
2024-02-27 2页
致敬半边天:巾帼风采铸就时代辉煌
2024-02-27 2页
世界水日日记
2024-02-27 2页
弘扬雷锋精神共建和谐社会
2024-02-27 2页
元宵节的热闹与温馨
2024-02-27 2页
2023-2024学年湖南省小学数学五年级期末通关试卷详细答案和解析
2024-02-20 20页
2023-2024学年浙江省宁波市初中生物八年级期末通关试卷详细答案和解析
2024-02-20 23页