
阿里和浙大的“AI 训练师助手”是这样炼成的.docx
9页
1、阿里和浙大的“AI 训练师助手”是这样炼成的简介:不久前,人力资源社会保障部发布了一种炙手可热的新职业:AI 训练师。没想到,浙江大学与阿里安全的人工智能训练师马上创造出一个 “AI 训练师助手”,高效打造 AI 深度模型,应对海量应用场景的增加,让 AI 训练模型面对新场景时不用从头学习,直接从已经存在的模型上迁移,迅速获得别人的知识、能力,成为全新的AI模型,而且能将模型周期从一个月缩短为一天。原文链接:点击这里不久前,人力资源社会保障部发布了一种炙手可热的新职业:AI 训练师。没想到,浙江大学与阿里安全的人工智能训练师马上创造出一个 “AI 训练师助手”,高效打造 AI 深度模型,应对海量应用场景的增加,让 AI 训练模型面对新场景时不用从头学习,直接从已经存在的模型上迁移,迅速获得别人的知识、能力,成为全新的AI模型,而且能将模型周期从一个月缩短为一天。随后,阐述这种让 AI 训练 AI,提升模型生产效率的论文被计算机视觉顶会 CVPR 2020 接收 (Oral)。现在,视频、直播成为互联网内容消费的重要载体,内容创作爆发,创作形式自由度高带来了许多潜在安全威胁。好消息是,A
2、I 深度模型被大规模用于多媒体内容的识别、检测、理解上,用以狙击含有不良内容的传播。为了提升检测的准确性,面向不同场景必须使用不同的 AI 模型。但是,由于媒体场景、细分领域多,如何才能高效生产不同 AI 深度模型?目前实现这一目标最流行的方法是迁移学习。浙江大学和阿里安全发现,两个预训练深度模型所提取的特征之间的迁移能力可由它们对应的深度归因图谱之间的相似性来衡量。相似程度越高,从不同的预训练深度模型中获得的特征相关性就越大,特征的相互迁移能力也就越强。而且,“AI 训练师助手”还知道从什么模型迁移知识,用模型的哪个部分迁移能最好地完成任务。也就是说,他们发现了让小白模型向 AI 深度模型学习的高效学习方法。问题:如何才能取得最优迁移效果得益于大量高质量标注数据、高容量的模型架构、高效率的优化算法以及高性能计算硬件的发展,过去十年里深度学习在计算机视觉、自然语言处理以及生物信息学等领域取得了举世瞩目的进步。随着深度学习取得了前所未有的成功,越来越多的科研人员和工业工作者愿意开源他们训练好的模型来鼓励业界进一步的研究。目前,预训练好的深度学习模型可以说是无处不在。阿里安全图灵实验室高级
3、算法专家析策认为,我们不仅处在一个大数据时代,同时也正在步入一个“大模型”时代。与大数据相似,海量模型形成的模型仓库也蕴含了巨大的潜在价值。这些预训练的深度模型已经消耗了大量的训练时间以及大规模高质量的标注数据等昂贵的计算资源。如果这些预训练的模型能够被合理地重新使用,那么在解决新任务时的对训练时间以及训练数据的依赖就会显著降低。目前实现这一目标最流行的方法就是迁移学习。在基于深度模型的跨任务的迁移学习中,模型微调是一种使用最广泛并且有效的方法。该方法以一个预先训练的模型作为起点,固定模型的一部分参数以降低模型优化空间,利用新任务有限的数据训练剩余的参数,使得模型能够在新任务上获得成功。虽然这种方法在一些具体问题中取得了一定的成效,但是当前这些迁移学习方法忽略了两个重要的问题:面对海量的预训练好的深度模型,选择哪个模型解决当前任务能够取得最好的效果;给定一个预训练好的模型,应该固定哪些层的参数以及优化哪些层才能够取得最优的迁移效果。目前的模型选择通常是盲目地采用 ImageNet 的预训练模型。然而,ImageNet 预训练的模型并不总是对所有任务产生令人满意的性能,特别是当任务与 I
4、mageNet 数据上定义的任务有显著差异时。而模型微调时参数优化临界点的选择往往依赖于经验。但是,由于最优的优化临界点取决于各种因素,如任务相关性和目标数据量等,依赖经验做出的选择往往很难保证最优。不同任务下深度神经网络提取特征的可迁移性为了解决上述问题,浙江大学和阿里安全发起了这项研究:在不同任务下训练的深度神经网络提取的特征之间的可迁移性。Zamir 等人1对不同任务间的迁移关系作了初步的研究。他们提出了一种全计算的方法,称为 taskonomy,来测量任务的可迁移性。然而, taskonomy 中有三个不可忽视的局限性,极大地阻碍了它在现实问题中的应用。首先,它的计算成本高得令人望而却步。在计算给定任务集合中两两任务之间的迁移关系时,计算成本会随集合中任务数量的增加而呈平方性地增长,当任务数量很大时,计算成本会变得非常昂贵。第二个限制是,它采用迁移学习来建立任务之间的迁移关系,这仍然需要大量的标记数据来训练转移模型。然而,在许多情况下,我们只能获取训练好的模型,并不能够获取到相应的训练数据。最后,taskonomy 只考虑不同模型或任务之间的可迁移性,而忽略了不同层之间的可迁移
《阿里和浙大的“AI 训练师助手”是这样炼成的.docx》由会员A***分享,可在线阅读,更多相关《阿里和浙大的“AI 训练师助手”是这样炼成的.docx》请在金锄头文库上搜索。
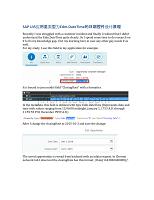
SAP UI5应用里类型为Edm.DateTime的日期控件设计原理.docx

SAP UI5 Web Component for React的图标和图片处理.docx
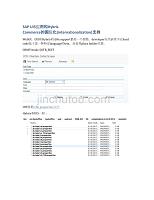
SAP UI5应用和Hybris Commerce的国际化(internationalization)支持.docx
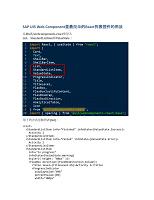
SAP UI5 Web Component里最简单的React列表控件的用法.docx

SAP UI5 Connection manager.docx

SAP UI5 jQuery.sap.setObject.docx

SAP WebClient UI drop down list(下拉列表)的一个故障和解决方法.docx

SAP UI5 GM6 require sap.ui.core.Core.docx
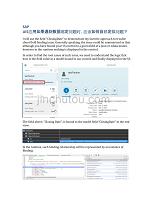
SAP UI5应用如果遇到数据绑定问题时应该如何自己定位问题?.docx
SAP云平台上的Mendix服务 - 如何注册帐号.docx

SAP Odata filter的语法.docx

SAP UI5和React的页面渲染性能比较.docx

SAP UI5 setModel of scFld Controller.docx

SAP Netweaver后台作业的几种状态.docx
SAP UI5 Opportunity popup.docx

SDL_FillRect函数.docx

SDL_Rect结构.docx

SAP UI5 component container initialized in index html.docx

SAP UI5应用里的列表处理.docx

SAP UI5 ResponsiveGridLayout.docx
 03.主播的定位
03.主播的定位
2024-01-15 24页
04.主播的账号
2024-01-15 15页
03060019IT容灾、研发及后援中心项目总承包施工招标文
2024-01-08 89页
GZIT2010-ZB0704广州市第八人民医院传染病临床数据管理系统项目
2024-01-08 72页
聘请SEO顾问的合同书
2023-08-31 3页
SEO专员工作内容
2023-08-31 2页
asic与verilog数字系统设计课程设计
2023-07-10 3页
ASP.NET上机练习与提高课程设计
2023-07-10 3页
AutoCAD计算机辅助设计课程设计
2023-07-10 3页
AutoCAD2013中文版实用教程教学设计
2023-07-10 2页