
基本回归模型课件
89页
1、2020/1/8,1,第六章 基本回归模型,单方程回归是最丰富多彩和广泛使用的统计技术之一。本章介绍EViews中基本回归技术的使用,说明并估计一个回归模型,进行简单的特征分析,并在深入的分析中使用估计结果。 计量经济学的一些更高级、专业的技术,如加权最小二乘法、二阶段最小二乘法(TSLS)、非线性最小二乘法、ARIMA/ARIMAX模型、GMM(广义矩估计)、GARCH模型和定性的有限因变量模型等,这些技术和模型都建立在本章介绍的基本思想的基础之上。,2020/1/8,2,主 要 内 容, 6.1 创建方程对象 6.2 在EViews中对方程进行说明 6.3 在EViews中估计方程 6.4 方程输出 6.5 方程操作 6.6 回归模型的其它函数形式 6.7 估计中存在的问题 6.8 定义和诊断检验 6.9 EViews中的方程预测,2020/1/8,3, 6.1 创建方程对象,EViews中的单方程回归估计是用方程对象来完成的。创建一个方程对象的方法: 从主菜单选择Object/New Object/Equation 或 Quick/Estimation Equation ,或者在
2、命令窗口中输入关键词equation。 在随后出现的方程说明对话框中说明要建立的方程,并选择估计方法。下面我们详细介绍在EViews中如何说明方程。EViews将在方程窗口中估计方程并显示结果。,2020/1/8,4, 6.2 在EViews中对方程进行说明,当创建一个方程对象时,会出现如下对话框:,在这个对话框中需要说明三件事:方程说明,估计方法,估计使用的样本。在最上面的编辑框中,可以说明方程:因变量(左边)和自变量(右边)以及函数形式。 有两种说明方程的基本方法:列表法和公式法。列表法简单但是只能用于不严格的线性说明;公式法更为一般,可用于说明非线性模型或带有参数约束的模型。,2020/1/8,5,6.2.1 列表法 说明线性方程的最简单的方法是列出方程中要使用的变量列表。首先是因变量或表达式名,然后是自变量列表。例如,要说明一个线性消费函数,用一个常数 c 和收入 inc 对消费 cs 作回归,在方程说明对话框上部输入: cs c inc 注意回归变量列表中的序列 c,这是EViews用来说明回归中的常数而建立的序列。EViews在回归中不会自动包括一个常数,因此必须明确列出作
3、为回归变量的常数。内部序列 c 不出现在工作文档中,除了说明方程外不能使用它。 在上例中,常数存储于c(1),inc的系数存储于c(2),即回归方程形式为: cs = c(1)+c(2)*inc。,2020/1/8,6,在实际操作中会用到滞后序列,可以使用与滞后序列相同的名字来产生一个新序列,把滞后值放在序列名后的括号中。 cs c cs(-1) inc 相当的回归方程形式为: cs = c(1)+ c(2) cs(-1)+c(3) inc。 通过在滞后中使用关键词 to 可以包括一个连续范围的滞后序列。例如:cs c cs(-1 to -4) inc 这是cs关于常数,cs(-1),cs(-2),cs(-3),cs(-4),和inc的回归。,在变量列表中也可以包括自动序列。例如: log(cs) c log(cs(-1) log(inc+inc(-1)/2) 相当的回归方程形式为: log(cs) = c(1)+c(2) log(cs(-1)+c(3) log(inc+inc(-1)/2),2020/1/8,7,6.2.2 公式法说明方程 当列表方法满足不了要求时,可以用公式来说明方
4、程。许多估计方法(但不是所有的方法)允许使用公式来说明方程。 EViews中的公式是一个包括回归变量和系数的数学表达式。要用公式说明一个方程,只需在对话框中变量列表处输入表达式即可。EViews会在方程中添加一个随机附加扰动项并用最小二乘法估计模型中的参数。,2020/1/8,8,用公式说明方程的好处是可以使用不同的系数向量。要创建新的系数向量,选择Object/New Object 并从主菜单中选择Matrix-Vector-Coef , 为系数向量输入一个名字,然后选择OK。在New Matrix对话框中,选择Coefficient Vector 并说明向量中应有多少行。带有系数向量图标的对象会列在工作文档目录中,在方程说明中就可以使用这个系数向量。例如,假设创造了系数向量A和BETA,各有一行。则可以用新的系数向量代替 c : log(cs)=A(1)+ BETA(1)* log(cs(-1),2020/1/8,9, 6.3 在EViews中估计方程,6.3.1 估计方法 说明方程后,现在需要选择估计方法。单击Method:进入对话框,会看到下拉菜单中的估计方法列表:,标准的单方
《基本回归模型课件》由会员灯火****19分享,可在线阅读,更多相关《基本回归模型课件》请在金锄头文库上搜索。

2019年湘阴县第三中学高考生物简单题专项训练(含解析)

2019年耿马县民族中学高考生物简单题专项训练(含解析)

2019年楚雄师院附中高考生物简单题专项训练(含解析)

2019年桥梁工程师年终总结
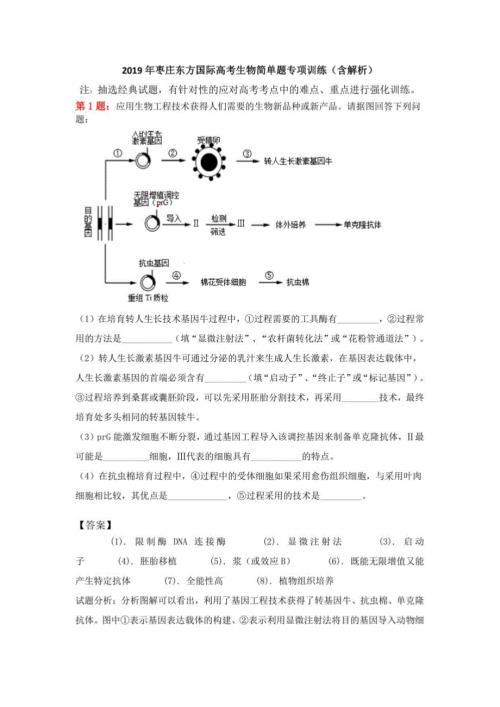
2019年枣庄东方国际高考生物简单题专项训练(含解析)

2018年一级建造师公路工程实务考点归纳

2019年赣榆县高考生物简单题专项训练(含解析)

2019年春湾中学高考生物简单题专项训练(含解析)

高考地理复习汇总

2019年朝鲜中学高考生物简单题专项训练(含解析)

2019年沧州市运河区派尼中学高考生物简单题专项训练(含解析)

2018年甘肃公务员《行政职业能力测验》试题(网友回忆版)

宾语从句 (解析卷)---2023年中考英语考点详解+专项训练

2018年一级建造师通信与广电实务考点

2019年湖北省襄阳市中考数学试卷(解析版)

文言文阅读(解析版)

中医综合模拟试卷343

2019年单县第二中学高考生物简单题专项训练(含解析)

二级法规考点解析1

2019年低碳经济继续教育模拟考试题库500题(含标准答案)
 企业高效开会秘诀
企业高效开会秘诀
2024-01-31 15页
管理者的职责认知
2024-01-31 21页
高效会议秘诀培训PPT
2024-01-31 37页
项目管理流程(5大过程)
2024-01-31 30页
商业分析工具:战略分析与规划工具(精品)
2024-01-31 22页
商业分析工具:由商业问题到最终成果
2024-01-31 48页
管理者的自我成长
2024-01-31 32页
项目管理流程培训PPT
2024-01-31 40页
商业分析工具:销售数据分析方法
2024-01-31 31页
会议管理知识
2024-01-31 20页